- Обзор самых популярных алгоритмов машинного обучения
- 1. Линейная регрессия
- 2 . Логистическая регрессия
- 3. Линейный дискриминантный анализ (LDA)
- 4. Деревья принятия решений
- 5 . Наивный Байесовский классификатор
- 6. K-ближайших соседей (KNN)
- 7 . Сети векторного квантования (LVQ)
- 8. Метод опорных векторов (SVM)
- 9 . Бэггинг и случайный лес
- 10 . Бустинг и AdaBoost
- Пара слов напоследок
- Вывод и предсказания. Часть 1: машинное обучение
- Пример: моделирование доли пользовательского отклика
- Взгляд на данные
- Предсказание — подход машинного обучения
- Сборка модели воедино
- “Обучение” из машинного обучения
- Обоснование отрицательного логарифмического правдоподобия
- Оптимизация — старый добрый градиентный спуск
- Статистика: “Но ведь это всего лишь…”
- Измерение эффективности модели машинного обучения
- Ограничения машинного обучения
- Проблема предсказания
Обзор самых популярных алгоритмов машинного обучения
![]()
Существует такое понятие, как «No Free Lunch» теорема. Её суть заключается в том, что нет такого алгоритма, который был бы лучшим выбором для каждой задачи, что в особенности касается обучения с учителем.
Например, нельзя сказать, что нейронные сети всегда работают лучше, чем деревья решений, и наоборот. На эффективность алгоритмов влияет множество факторов вроде размера и структуры набора данных.
По этой причине приходится пробовать много разных алгоритмов, проверяя эффективность каждого на тестовом наборе данных, и затем выбирать лучший вариант. Само собой, нужно выбирать среди алгоритмов, соответствующих вашей задаче. Если проводить аналогию, то при уборке дома вы, скорее всего, будете использовать пылесос, метлу или швабру, но никак не лопату.
MyTona , Удалённо , По итогам собеседования
Алгоритмы машинного обучения можно описать как обучение целевой функции f , которая наилучшим образом соотносит входные переменные X и выходную переменную Y : Y = f(X) .
Мы не знаем, что из себя представляет функция f . Ведь если бы знали, то использовали бы её напрямую, а не пытались обучить с помощью различных алгоритмов.
Наиболее распространённой задачей в машинном обучении является предсказание значений Y для новых значений X . Это называется прогностическим моделированием, и наша цель — сделать как можно более точное предсказание.
Представляем вашему вниманию краткий обзор топ-10 популярных алгоритмов, используемых в машинном обучении.
1. Линейная регрессия
Линейная регрессия — пожалуй, один из наиболее известных и понятных алгоритмов в статистике и машинном обучении.
Прогностическое моделирование в первую очередь касается минимизации ошибки модели или, другими словами, как можно более точного прогнозирования. Мы будем заимствовать алгоритмы из разных областей, включая статистику, и использовать их в этих целях.
Линейную регрессию можно представить в виде уравнения, которое описывает прямую, наиболее точно показывающую взаимосвязь между входными переменными X и выходными переменными Y . Для составления этого уравнения нужно найти определённые коэффициенты B для входных переменных.
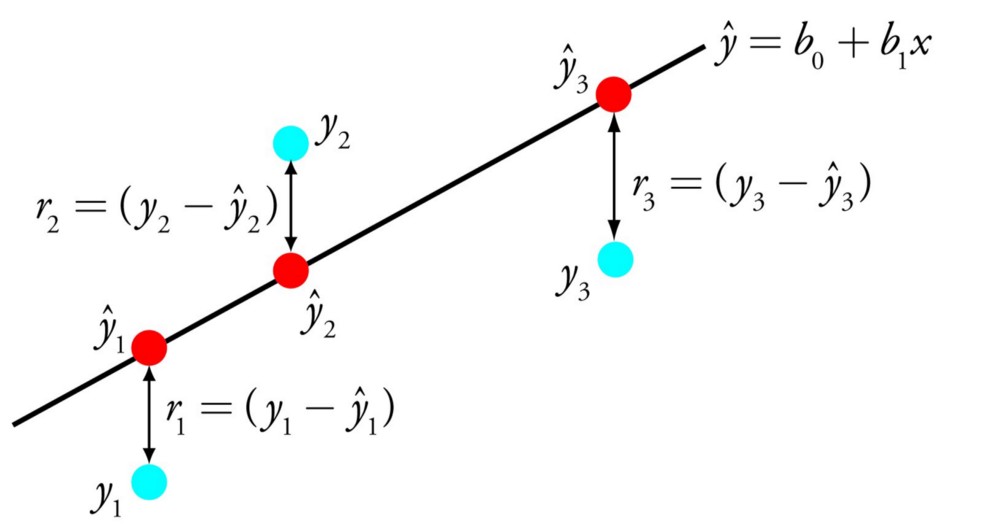
Например: Y = B0 + B1 * X
Зная X , мы должны найти Y , и цель линейной регрессии заключается в поиске значений коэффициентов B0 и B1 .
Для оценки регрессионной модели используются различные методы вроде линейной алгебры или метода наименьших квадратов.
Линейная регрессия существует уже более 200 лет, и за это время её успели тщательно изучить. Так что вот пара практических правил: уберите похожие (коррелирующие) переменные и избавьтесь от шума в данных, если это возможно. Линейная регрессия — быстрый и простой алгоритм, который хорошо подходит в качестве первого алгоритма для изучения.
2 . Логистическая регрессия
Логистическая регрессия — ещё один алгоритм, пришедший в машинное обучение прямиком из статистики. Её хорошо использовать для задач бинарной классификации (это задачи, в которых на выходе мы получаем один из двух классов).
Логистическая регрессия похожа на линейную тем, что в ней тоже требуется найти значения коэффициентов для входных переменных. Разница заключается в том, что выходное значение преобразуется с помощью нелинейной или логистической функции.
Логистическая функция выглядит как большая буква S и преобразовывает любое значение в число в пределах от 0 до 1. Это весьма полезно, так как мы можем применить правило к выходу логистической функции для привязки к 0 и 1 (например, если результат функции меньше 0.5, то на выходе получаем 1) и предсказания класса.
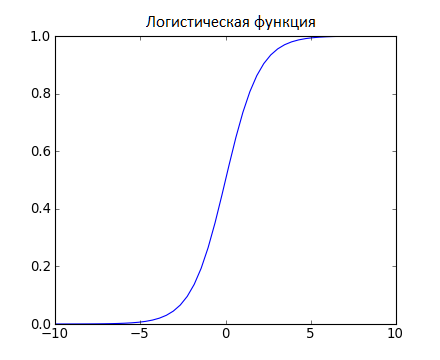
Благодаря тому, как обучается модель, предсказания логистической регрессии можно использовать для отображения вероятности принадлежности образца к классу 0 или 1. Это полезно в тех случаях, когда нужно иметь больше обоснований для прогнозирования.
Как и в случае с линейной регрессией, логистическая регрессия выполняет свою задачу лучше, если убрать лишние и похожие переменные. Модель логистической регрессии быстро обучается и хорошо подходит для задач бинарной классификации.
3. Линейный дискриминантный анализ (LDA)
Логистическая регрессия используется, когда нужно отнести образец к одному из двух классов. Если классов больше, чем два, то лучше использовать алгоритм LDA (Linear discriminant analysis).
Представление LDA довольно простое. Оно состоит из статистических свойств данных, рассчитанных для каждого класса. Для каждой входной переменной это включает:
- Среднее значение для каждого класса;
- Дисперсию, рассчитанную по всем классам.
Предсказания производятся путём вычисления дискриминантного значения для каждого класса и выбора класса с наибольшим значением. Предполагается, что данные имеют нормальное распределение, поэтому перед началом работы рекомендуется удалить из данных аномальные значения. Это простой и эффективный алгоритм для задач классификации.
4. Деревья принятия решений
Дерево решений можно представить в виде двоичного дерева, знакомого многим по алгоритмам и структурам данных. Каждый узел представляет собой входную переменную и точку разделения для этой переменной (при условии, что переменная — число).
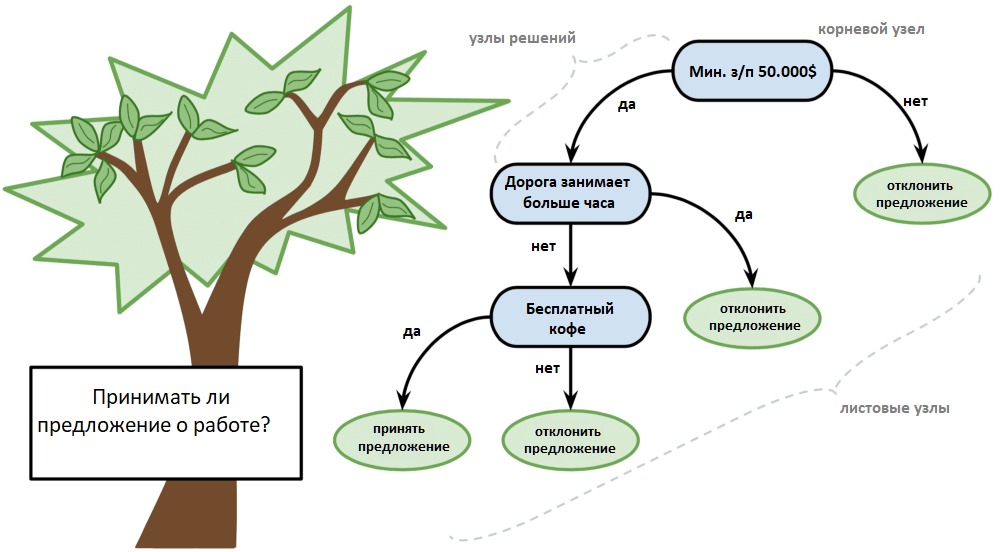
Листовые узлы — это выходная переменная, которая используется для предсказания. Предсказания производятся путём прохода по дереву к листовому узлу и вывода значения класса на этом узле.
Деревья быстро обучаются и делают предсказания. Кроме того, они точны для широкого круга задач и не требуют особой подготовки данных.
5 . Наивный Байесовский классификатор
Наивный Байес — простой, но удивительно эффективный алгоритм.
Модель состоит из двух типов вероятностей, которые рассчитываются с помощью тренировочных данных:
- Вероятность каждого класса.
- Условная вероятность для каждого класса при каждом значении x.
После расчёта вероятностной модели её можно использовать для предсказания с новыми данными при помощи теоремы Байеса. Если у вас вещественные данные, то, предполагая нормальное распределение, рассчитать эти вероятности не составляет особой сложности.
Наивный Байес называется наивным, потому что алгоритм предполагает, что каждая входная переменная независимая. Это сильное предположение, которое не соответствует реальным данным. Тем не менее данный алгоритм весьма эффективен для целого ряда сложных задач вроде классификации спама или распознавания рукописных цифр.
6. K-ближайших соседей (KNN)
К-ближайших соседей — очень простой и очень эффективный алгоритм. Модель KNN (K-nearest neighbors) представлена всем набором тренировочных данных. Довольно просто, не так ли?
Предсказание для новой точки делается путём поиска K ближайших соседей в наборе данных и суммирования выходной переменной для этих K экземпляров.
Вопрос лишь в том, как определить сходство между экземплярами данных. Если все признаки имеют один и тот же масштаб (например, сантиметры), то самый простой способ заключается в использовании евклидова расстояния — числа, которое можно рассчитать на основе различий с каждой входной переменной.
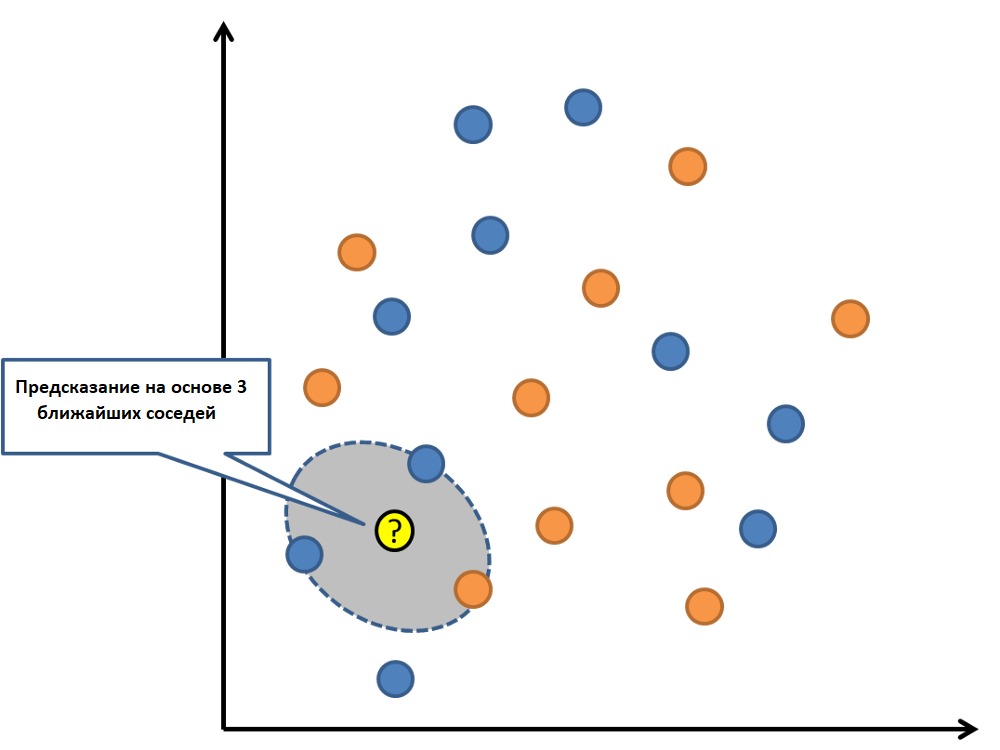
KNN может потребовать много памяти для хранения всех данных, но зато быстро сделает предсказание. Также обучающие данные можно обновлять, чтобы предсказания оставались точными с течением времени.
Идея ближайших соседей может плохо работать с многомерными данными (множество входных переменных), что негативно скажется на эффективности алгоритма при решении задачи. Это называется проклятием размерности. Иными словами, стоит использовать лишь наиболее важные для предсказания переменные.
7 . Сети векторного квантования (LVQ)
Недостаток KNN заключается в том, что нужно хранить весь тренировочный набор данных. Если KNN хорошо себя показал, то есть смысл попробовать алгоритм LVQ (Learning vector quantization), который лишён этого недостатка.
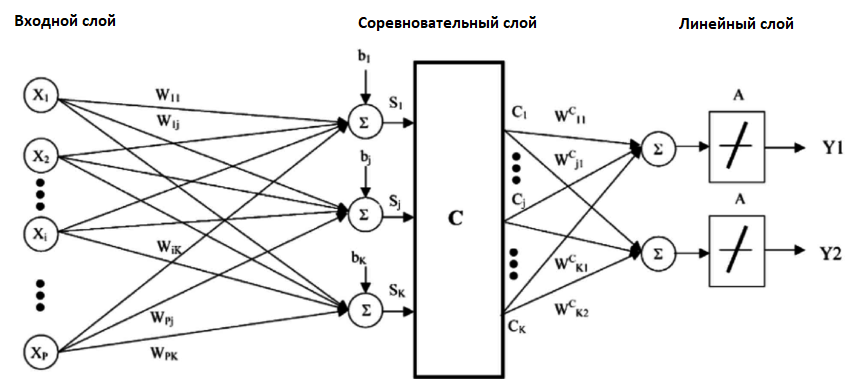
LVQ представляет собой набор кодовых векторов. Они выбираются в начале случайным образом и в течение определённого количества итераций адаптируются так, чтобы наилучшим образом обобщить весь набор данных. После обучения эти вектора могут использоваться для предсказания так же, как это делается в KNN. Алгоритм ищет ближайшего соседа (наиболее подходящий кодовый вектор) путём вычисления расстояния между каждым кодовым вектором и новым экземпляром данных. Затем для наиболее подходящего вектора в качестве предсказания возвращается класс (или число в случае регрессии). Лучшего результата можно достичь, если все данные будут находиться в одном диапазоне, например от 0 до 1.
8. Метод опорных векторов (SVM)
Метод опорных векторов, вероятно, один из наиболее популярных и обсуждаемых алгоритмов машинного обучения.
Гиперплоскость — это линия, разделяющая пространство входных переменных. В методе опорных векторов гиперплоскость выбирается так, чтобы наилучшим образом разделять точки в плоскости входных переменных по их классу: 0 или 1. В двумерной плоскости это можно представить как линию, которая полностью разделяет точки всех классов. Во время обучения алгоритм ищет коэффициенты, которые помогают лучше разделять классы гиперплоскостью.
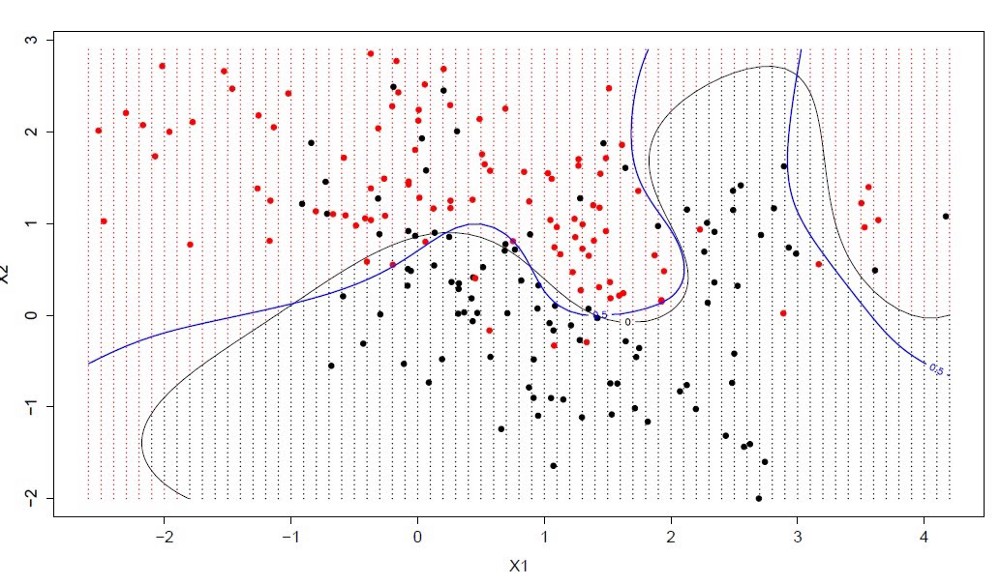
Расстояние между гиперплоскостью и ближайшими точками данных называется разницей. Лучшая или оптимальная гиперплоскость, разделяющая два класса, — это линия с наибольшей разницей. Только эти точки имеют значение при определении гиперплоскости и при построении классификатора. Эти точки называются опорными векторами. Для определения значений коэффициентов, максимизирующих разницу, используются специальные алгоритмы оптимизации.
Метод опорных векторов, наверное, один из самых эффективных классических классификаторов, на который определённо стоит обратить внимание.
9 . Бэггинг и случайный лес
Случайный лес — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом.
Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения.
В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению.
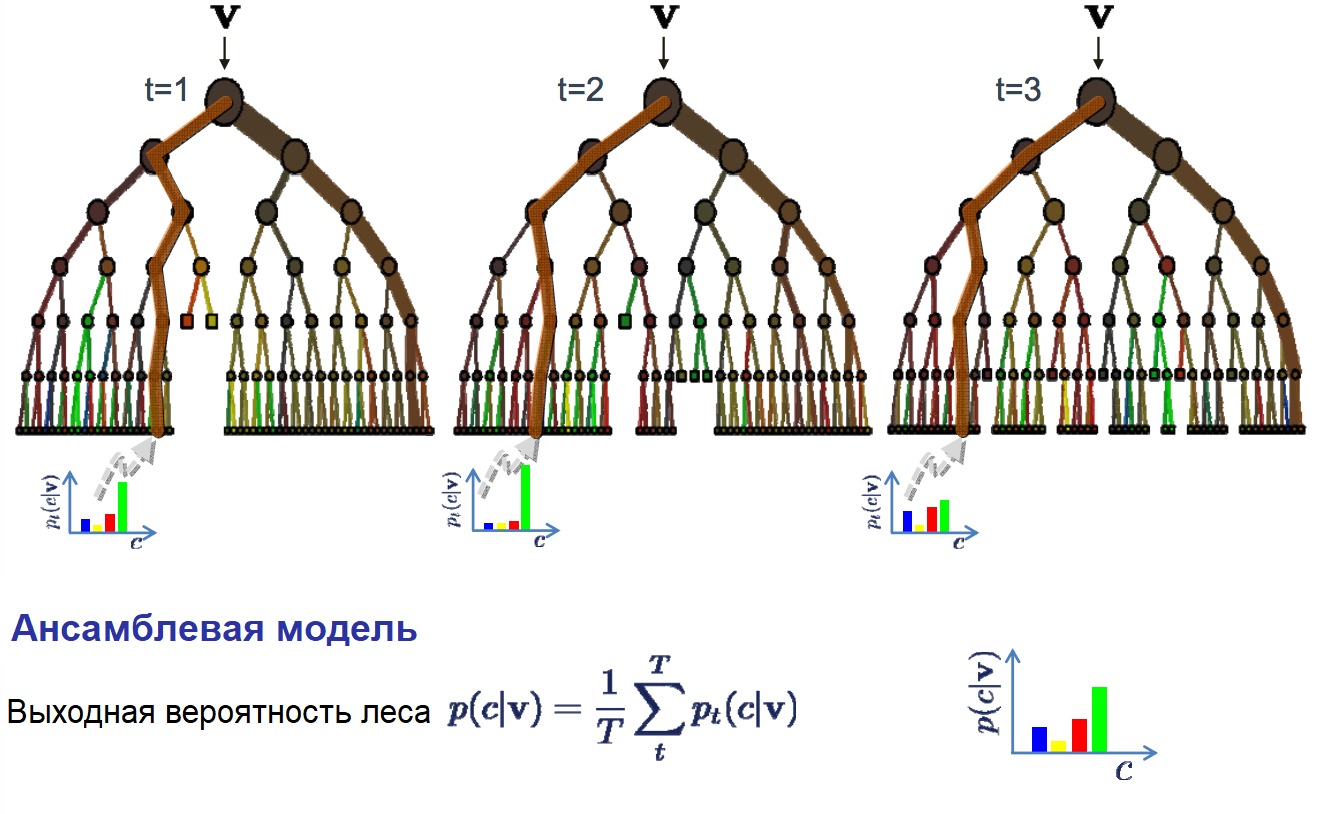
В алгоритме случайного леса для всех выборок из тренировочных данных строятся деревья решений. При построении деревьев для создания каждого узла выбираются случайные признаки. В отдельности полученные модели не очень точны, но при их объединении качество предсказания значительно улучшается.
Если алгоритм с высокой дисперсией, например, деревья решений, показывает хороший результат на ваших данных, то этот результат зачастую можно улучшить, применив бэггинг.
10 . Бустинг и AdaBoost
Бустинг — это семейство ансамблевых алгоритмов, суть которых заключается в создании сильного классификатора на основе нескольких слабых. Для этого сначала создаётся одна модель, затем другая модель, которая пытается исправить ошибки в первой. Модели добавляются до тех пор, пока тренировочные данные не будут идеально предсказываться или пока не будет превышено максимальное количество моделей.
AdaBoost был первым действительно успешным алгоритмом бустинга, разработанным для бинарной классификации. Именно с него лучше всего начинать знакомство с бустингом. Современные методы вроде стохастического градиентного бустинга основываются на AdaBoost.
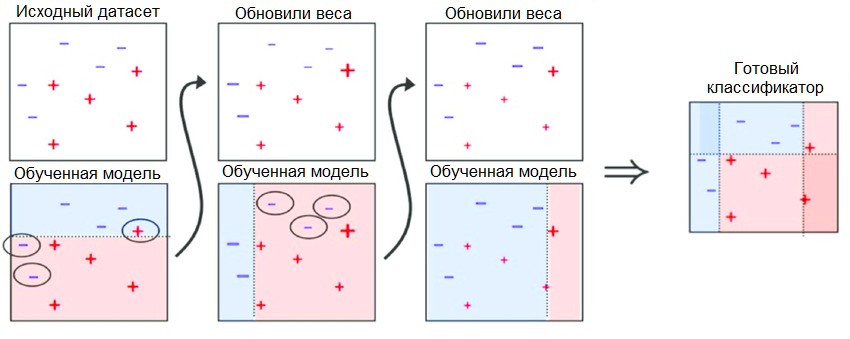
AdaBoost используют вместе с короткими деревьями решений. После создания первого дерева проверяется его эффективность на каждом тренировочном объекте, чтобы понять, сколько внимания должно уделить следующее дерево всем объектам. Тем данным, которые сложно предсказать, даётся больший вес, а тем, которые легко предсказать, — меньший. Модели создаются последовательно одна за другой, и каждая из них обновляет веса для следующего дерева. После построения всех деревьев делаются предсказания для новых данных, и эффективность каждого дерева определяется тем, насколько точным оно было на тренировочных данных.
Так как в этом алгоритме большое внимание уделяется исправлению ошибок моделей, важно, чтобы в данных отсутствовали аномалии.
Пара слов напоследок
Когда новички видят всё разнообразие алгоритмов, они задаются стандартным вопросом: «А какой следует использовать мне?» Ответ на этот вопрос зависит от множества факторов:
- Размер, качество и характер данных;
- Доступное вычислительное время;
- Срочность задачи;
- Что вы хотите делать с данными.
Даже опытный data scientist не скажет, какой алгоритм будет работать лучше, прежде чем попробует несколько вариантов. Существует множество других алгоритмов машинного обучения, но приведённые выше — наиболее популярные. Если вы только знакомитесь с машинным обучением, то они будут хорошей отправной точкой.
Источник
Вывод и предсказания. Часть 1: машинное обучение
January 12, 2021 15 мин на чтение
Это первая статья из трех, посвященных разнице между выводом и предсказанием в моделировании данных. Также мы разберем разницу между машинным обучением и статистикой. За мою карьеру аналитика данных я обнаружил удивительное непонимание понятия вывода, который обычно понимается как часть статистики. Я также понял, что, хотя это менее распространено, профессиональные статистики не очень хорошо понимают, как машинное обучение ставит задачи предсказания.
Немногим более года назад я запостил картинку в Твиттере, которая отражает мое понимание этих понятий:
В этой серии статей мы увидим, что эти два понятия связаны больше, чем обычно представляют.
В первой статье я бы хотел не только наметить общую идею через рабочий пример, но и попытаться сблизить эти два понятия. Конечной целью каждого исследователя должно быть рассмотрение моделирование как системного процесса, использующего все возможности математических рассуждений. Процесс моделирования должен быть интерактивным, выходящим за рамки этих двух понятий, что особенно актуально в наш век доступных вычислительных возможностей.
Пример: моделирование доли пользовательского отклика
Одна из самых распространенных проблем в индустрии — это моделирование доли пользовательского отклика (Click Through Rate, CTR). Обычно проблема CTR возникает, когда мы оцениваем выполнение пользователем определенных действий: подписка на сервис через форму, щелчки по рекламе, просмотр описания товаров в каталоге, покупка товаров, чтение постов в агрегаторе, и так далее.
В предыдущей статье мы говорили о процессе сэмплирования Томпсона при оптимизации рекламных аукционов. Одна из ключевых частей той статьи была посвящена оценке CTR с помощью бета-распределения, зная только предыдущее соотношение кликов и просмотров. И хотя этот подход прекрасно работает, обычно у нас есть много дополнительной информации, которую можно использовать для более точного понимания пользовательского отклика.
В этом примере мы будем использовать информацию об откликах пользователей на объявления о вакансиях с сайта объявлений. Данные взяты из этого набора с Kaggle. Мы используем эти данные для моделирования того, откликнется ли пользователь на данное объявление о вакансии, исходя из его категории, и того, насколько соответствует заголовок объявления пользовательской строке запроса.
На протяжении всей моей карьеры в анализе данных меня удивляет то, насколько часто эти задачи трактуются как чисто предсказательные. Как мы увидим в этой статье, исключительно предсказательный подход к проблеме CTR приводит к ограниченности того, как можно решать разные задачи, относящиеся к этой проблеме (а именно, как повысить отклики!). Для начала мы подойдем к этой задаче с точки зрения машинного обучения, построив простой персептрон на Python и JAX, а затем, в следующей части, расширим эту модель для решения задачи вывода.
Взгляд на данные
Прежде чем мы начнем, взглянем на очищенные данные из нашего набора. Вот какие признаки мы будем использовать:
Первые три признака описывают разные метрики близости строки поиска пользователя и заголовка объявления о вакансии, следующий — возраст объявления в днях, а затем у нас идут 10 самых распространенных категорий объявлений как индикация того, принадлежит ли данное объявление к этой категории.
Вот как выглядят данные, уже приведенные к стандартному нормальному распределению:
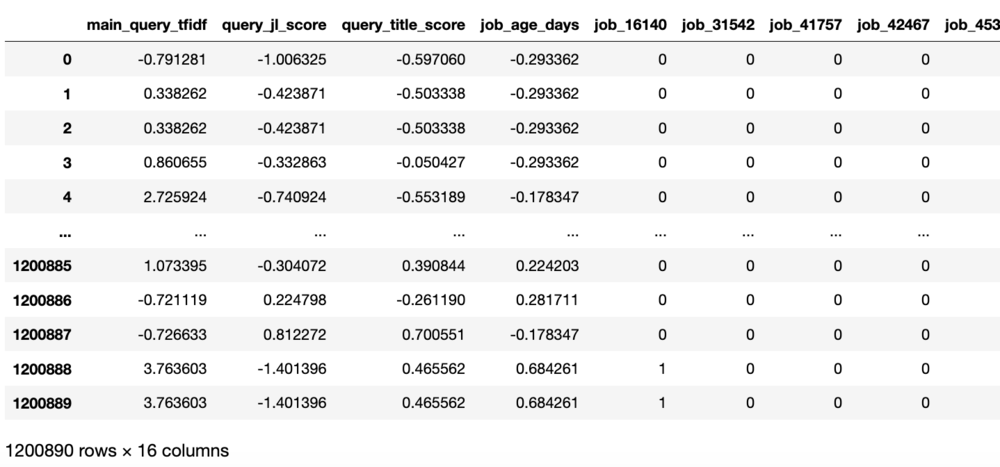
Как Вы видите, у нас достаточно данных — 1 200 890 строк.
Далее мы будем производить множество вычислений по этим данным, так что приведем их в формат матрицы jax и разделим на обучающую и тестовую выборки:
Теперь можем начинать моделирование!
Предсказание — подход машинного обучения
Теперь когда мы полностью подготовили данные, время заняться моделированием! Если вы опытный аналитик данных или эксперт по машинному обучению, большая часть этой статьи будет вам знакома. Это намеренно, так как я хочу показать логику, которая связывает традиционных взгляд с точки зрения машинного обучения со взглядом статистическим. Так что, хотя тема и знакома, стоит повторить, как именно мы думаем о решении проблем машинного обучения.
Так как мы занимаемся машинным обучением, хочется начать с нейронной сети. Но мы хотим начать с чего-то разумно простого, так что выберем самый простой тип нейронных сетей: персептрон. Если вы незнакомы с персептроном — это просто нейронная сеть без скрытых слоев. Вот иллюстрация нашей модели:
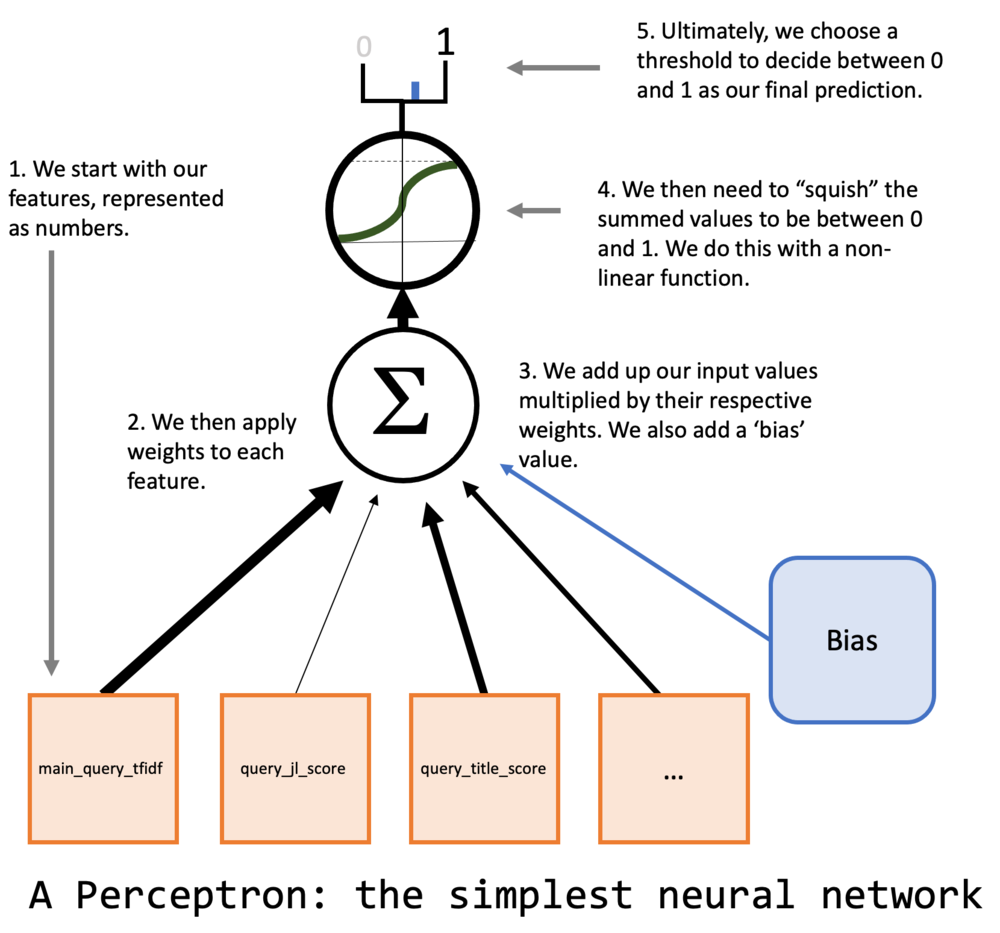
Обратите внимание на элемент “bias” или “смещение” на картинке. Мы можем его представить, добавив постоянный признак к нашему набору данных, что я уже сделал с массивами X_train и X_test.
Сборка модели воедино
Давайте подумаем о математике, лежащей в основе нашей модели. У нас есть графическое представление того, как устроен персептрон, на нам нужно понять, как заставить его работать в коде. У нас есть массивы X и y, то есть, соответственно, данные и целевая переменная. Нужно добавить кое-то еще.
Первый шаг — это представление всех линий на нашей диаграмме численно. Мы сделаем это с помощью вектора весов w. Но какие значения должны быть у этого вектора? Вот их как раз мы и хотим подобрать, или, как говорят, обучить (точнее мы хотим, чтобы машина их обучила).
Мы опять используем для этого jax, и для начала сгенерируем случайные веса. В отличие от обычного numpy, jax всегда требует ключ для генерации случайных значений. Это значит, что случайные переменные будут предсказуемыми. Это очень полезно при отладке нашей модели, ведь мы будем производить много случайных действий, а так они могут быть воспроизведены в точности. Вот пример того, как можно создать массив случайных весов:
Линии на диаграмме соответствуют перемножению значений признаков данных с весами и их суммированию. Математически мы можем представить перемножение и суммирование очень просто при помощи линейной алгебры:
В коде это тоже довольно просто получается:
Но мы еще не закончили. Есть одна заметная проблема. Мы хотим предсказывать 1 (если пользователь откликнется на вакансию) или 0 (если нет), так что нам нужен способ убедиться, что все наши предсказания находятся в этом диапазоне. Для этого нам понадобится нелинейная функция, которая сожмет получаемые значения в диапазон от 0 до 1. Используя g для обозначения этой функции, мы можем представить полное математическое представление персептрона как:
Самым простым вариантом для g будет логистическая функция, которая как раз выдает значения от 0 до 1. Кроме того, выдаваемые ей значения могут быть интерпретированы как вероятности. Мы еще этого коснемся во второй части, но это важно для будущего обучения нашей модели. Вот математическое выражение логистической функции:
А вот то же самое в коде:
Можем теперь применить это к X и случайным весам и получим нашу первую модель!
Это, по сути дела, именно случайные угадывания. Следующий шаг — попробовать улучшить их.
“Обучение” из машинного обучения
Конечно, наша модель пока ничего не знает о мире. Можно заметить, что она почти всегда выдает близке к 0,5 значения, ровно посередине между нашими вариантами 0 и 1. При предсказании мы обычно выбираем (точнее за нас выбирает программный инструмент) 0,5 как пороговое значение между этими вариантами. Так что пока примерно половина случаев будет определяться как предполагаемое наличие отклика, а половина — как отсутствие. Результат может немного отличаться из-за неравномерности распределения данных, но по сути мы просто умножаем равномерно распределенные случайные значения (веса модели) на значения, приведенные к стандартному распределению. Если подставить среднее значение — 0 в логистическую функцию, как раз и получается 0,5. Естественно, эти веса надо поменять со случайных на такие, которые лучшим образом преобразуют данные в нужный результат.
Можно иронизировать над названием “машинное обучение” для такого простого случая, но он даст нам хорошее описание используемых алгоритмов. Мы хотим, чтобы машина (то есть компьютер) обучилась лучшим w для нашей модели. Ключ к этому в том, чтобы дать понять машине, что один набор весов лучше или хуже другого. Мы добьемся этого, создав целевую функцию (ее еще называют функция потерь), которая определяет, насколько удачны изменения в модели.
Мы уже упоминали, что преимущество использования логистической функции в том, что мы может воспринимать ее значения как вероятности. Так значение 0,2 значит, что вероятность отклика на вакансию составляет 20%, а значение 0,75 — что 75%. Значения целевой переменной тоже так работают. Если мы знаем, что пользователь не ответил на вакансию, мы можем сказать, что вероятность ответа составила 0, а если ответил, то вероятность достоверного события равна 1.
Так можно понять, как сконструировать целевую функцию, которую мы будем оптимизировать. Если модель выдает 0.75, мы можем спросить, “Какова вероятность получения 1, если мы считаем, что вероятность отклика равна 75%?”
Очевидно, это просто 0,75. И наоборот, если модель выдает 0,75 а у нас записано 0, вероятность того, что модель верна всего 25%. Мы хотим получить такую функцию, которая вычисляет, насколько вероятны известные нам исходы при данных значениях весов. Как только мы ее получим, останется только найти веса, которые лучше всего объясняют известные нам данные. Это подход максимального правдоподобия для нахождения лучших весов.
Обоснование отрицательного логарифмического правдоподобия
Пока мы говорили о нахождении правдоподобие единственной точки данных, но нам нужен способ подсчитать это для всех 840 623 строк из обучающей выборки. Вот пример кода, который вычисляет правдоподобие данных при имеющихся весах для всего обучающего набора (p_d_h означает Probability of Data given the Hypothesis, вороятность данных при гипотезе):
Каждое значение представляет, насколько вероятен наблюдаемый исход, если предположить, что модель верна.
Мы хотим объединить их все в единое значение правдоподобия данных для конкретной модели. Мы могли бы для этого просто перемножить их:
Это соответствует полной вероятности всех наблюдений при верности нашей модели.
И хотя это математически корректно, можно быстро увидеть проблему:
Так как мы берем произведение более 800 000 вероятностей, полученный результат меньше минимального числа, которое может быть представлено в компьютере. Вероятность случайных весов получилась равна нулю, но даже если бы у нас была прекрасная модель, дающая, скажем, вероятность правильного прогноза 0,99, все равно получилось бы:
Что для компьютера все равно 0.
Хорошее решение этой проблемы — это взять логарифм каждой вероятности и суммировать их вместо того, чтобы перемножать. Это даст нам логарифмическое правдоподобие, что гораздо удобнее при использовании компьютера. Как мы видим, логарифмическое правдоподобие считается более содержательно:
Осталась одна проблема с этим значением. Обычно, оптимизационные алгоритмы находят минимальное значение выпуклой функции. Чем меньше наше значение, тем ниже правдоподобие модели, а нам нужно наоборот. К счастью, логарифмическое правдоподобие всегда отрицательно (так как обычное значение правдоподобия всегда меньше единицы), так что мы может просто взять противоположное значение.
Вот все это в виде одной функции:
Теперь мы можем посчитать отрицательное логарифмическое правдоподобие имеющихся данных для наших весов, еще до начала какого-либо обучения:
Как видно, отрицательное правдоподобие — это положительное число (ведь логарифм числа между 0 и 1 отрицателен). Теперь нам нужно найти такие значения весов w, которые уменьшают это значение, а значит увеличивают вероятность получения из весов известных нам данных.
Оптимизация — старый добрый градиентный спуск
Машина уже почти готова обучаться! Полезно думать о весах w, как определенной модели. С помощью отрицательного логарифмического правдоподобия мы можем различать, какая модель лучше или хуже — а именно, когда это значение ниже.
Мы имеем классическую оптимизационную задачу: необходимо последовательно понижать значение отрицательного правдоподобия до тех пор, пока мы не найдем значение, которое покажется нам самым низким. Мы будем использовать метод градиентного спуска — алгоритм нахождения минимума функции при помощи производной.
Так что осталось найти производную функции отрицательного логарифмического правдоподобия. Раньше нахождение градиента было трудной задачей, так как приходилось все производные считать руками. JAX делает эту процедуру тривиальной:
В этом коде мы получаем производную функции neg_log_likelihood по второму аргументу (нумерация начинается с нуля), то есть по весам w.
Далее мы создадим простую версию алгоритма градиентного спуска. Учитывая долгую популярностей нейронных сетей, существует большое количество учебников, разъясняющих детали этого метода, так что не будем в них вдаваться. Общая идея в том, что при помощи производной можно спускаться по значению функции до тех пор, пока мы не окажемся в локальном минимуме.
Добавим еще один шаг для более эффективного вычисления градиента:
Так как наша реализация обучения весьма схематичная, можно просто повторить градиентный спуск несколько раз до тех пор, пока получаемые значения не сойдутся к чему-нибудь.
Вот теперь мы обучили модель! Теперь надо посмотреть, насколько точно она описывает известные данные о пользовательских откликах на вакансии.
Статистика: “Но ведь это всего лишь…”
Хочу сделать небольшое отступление, чтобы обратиться к одному весьма распространенному среди специалистов по статистике заблуждению. Статистики сразу же распознают, что наша реализация персептрона полностью эквивалента логистической регрессии (подробнее об этом во второй части). Распространенное возражение со стороны статистики звучит так:
“Разве это и есть машинное обучение? Это же просто логистическая регрессия, которую мы применяем уже давно, не особо задумываясь обо все этом!”
Я поспорю, что важное отличие подхода машинного обучения в том, что мы действительно задумываемся обо все этом. О процессе оптимизации, о выборе функции потерь, о выборе метода оптимизации — все это неотъемлемая часть процесса моделирования. Например, для обычной линейной регрессии статистики наверняка прибегнут к методу наименьших квадратов. Это аналогично выбору среднеквадратической ошибка в качестве функции потерь, а это этого зависит, что мы можем делать при помощи нашей модели.
При увеличении сложности моделей вопросы о целевой функции и методах оптимизации выходят на первый план. Но даже в таком простом примере как наш функция отрицательного логарифмического правдоподобия была выбрана неслучайно, хотя существует множество способов обучиться практически тем же весам w. В следующих частях эта целевая функция позволит нам расширять модель с минимальным изменением кода.
Мы видим, что сама статистика трансформируется в этом направлении. Почти все работы в передовой области байесовского вывода требуют глубокого понимания алгоритмов оптимизации и численных методов. Другими словами, этот фокус на вычислимости и оптимизации и отличает машинное обучение от статистики.
Измерение эффективности модели машинного обучения
Сейчас полезно остановиться и подумать, что именно мы хотим измерять при оценке эффективности нашей модели. Конечная цель систем машинного обучения — предсказание какой-либо величины. Сейчас она выдает число от нуля до единицы, которые и составляет предсказание модели.
Эта модель также является классификатором. Мы представляем, что модель предсказывает, откликнется ли пользователь на данное объявление или нет. При построении классификатора мы добавим последнее преобразование, которое и будет решать, выдать 1 или 0 в качестве конечного результата.
Существует множество метрик эффективности моделей. Когда мы имеем дело с классификацией, естественно воспользоваться метрикой точности — отношением правильно сделанных предсказаний к их общему количеству. Но с этим методом есть две сложности. Первая становится очевидной, если мы подсчитаем долю откликов к общему количеству просмотров:
Так что у нас здесь присутствует классическая проблема несбалансированных классов (хотя, мне кажется это странным отношением к ситуации, особенно учитывая, что мы моделируем долю отклика). Проблема в том, что просто предсказывая 0 для всех случаев даст весьма неплохую оценку точности.
Другая, менее явная проблема связана с тем, что мы по-настоящему еще не задумывались о том, как выбирать ответ 0 или 1. Почти во всех библиотеках алгоритмов машинного обучения порог выбора задан неявно как 0,5. И это почти всегда настраивается, но я встречал немало озадаченных взглядов от аналитиков после вопроса “какое пороговое значение используется в вашей модели?”. Более формально этот параметр задается минимальным softmax слоем нейронной сети.
Но мы обычно не знаем заранее, какое значение порога даст нам наилучшие предсказания пользовательских откликов, так что мы используем специальную метрику, показывающую, насколько хорошо работает одна и та же модель при разных значениях порога — ROC AUC (эта метрика заслуживает специального обсуждения в отдельной статье).
Если вы с ней незнакомы, ROC AUC вычисляет площадь под графиком функции соотношения истинноположительных и ложноположительных долей предсказаний при различных значениях порога. Обычно, ROC AUC 0,5 означает, что наш классификатор все равно, что угадывает результат, а значение 1,0 свидетельствует об идеальной классификации.
Давайте посмотрим на вычисление метрик обучающих и тестовых данных:
Получилось не хорошо. Такое значение говорит о том, что наш классификатор не может эффективно разделить пользователей, которые откликаются на вакансии от остальных. Может показаться, что наша модель провалилась.
Ограничения машинного обучения
Но действительно, так ли она плоха? Давайте для начала посмотрим, как мы обучились. Конечное правдоподобие было -251,422, а в начале — -619,300. Помним, что
Это значит, что мы улучшили изначальное правдоподобие вот во сколько раз:
После обучения наша модель описывает данные лучше настолько, что мы даже не можем выразить коэффициент улучшения на компьютере! Так что мы многому научились.
Действительная проблема в том, как мы судим нашу модель. Точность, AUC, полнота, F1 — это все распространенные метрики для классификаторов. А мы в самом начале говорили о моделировании доли. Для моделирования долей и распределений всегда использовалась статистика.
Интерпретация задач моделирования распределений как задачи классификации — это одна из самых распространенных ошибок, которые я видел в машинном обучении. Сверхчеловеческая, идеальная модель распределения зачастую будет плохим классификатором.
Прекрасный пример этого — подбрасывание монеты. Если монета честная, и наша модель предсказывает вероятность выпадения орла ровно 0,5 без каких-либо неопределенностей, у нас есть идеальная модель поведения монеты. Но она же будет показывать ужасные результаты, если ее рассматривать как классификатор. Аналогично, представьте себе лотерею с шансом выигрыша в 1 / 1 000 000. Если ваша модель показывает точно и определенно шанс в 1 / 1 000 000, у вас прекрасная модель распределения. Но она будет отвратительным классификатором.
Даже если модели не работают как классификаторы, они могут дать нам ценную информацию для принятия решения в условиях неопределенности. Без правильной модели монеты мы можем принять неправильное решение о том, стоит ли ставить один доллар на монету, если при выпадении орла мы получим 2,1 доллара.
Проблема предсказания
Но проблема лежит глубже простого непонимания разницы моделирования распределения и классификации. Ведь мы можем рассматривать результат работы модели еще до применения порога принятия решения. Мы могли бы придумать какую-нибудь метрику, точнее измеряющую результат работы модели.
Но даже с этими изменениями, в конечном итоге модель дает нам всего лишь одно предсказание, точечную оценку отклика при имеющейся у нас информации. Любой сведущий человек сразу же спросит: “Насколько мы уверены в этой оценке?” Этот вопрос особенно актуален, если мы занимаемся чем-то вроде оптимизации рекламных аукционов или выплат премий за неопределенный риск. На такой вопрос отвечает статистический вывод.
Но обращаясь к выводу, нам придется обратить более пристальное внимание на то, чему именно обучилась наша модель. Это важно, так как распределения не существует в данных априорно — это часть нашей модели. Для понимания задач распределения необходимо понимать саму модель, а не только ее результаты.
Источник

