- Временные ряды. Простые решения
- План статьи
- Краткое описание тренажера
- Решение в лоб
- Добавление экзогенных переменных
- Коррекция гетероскедастичности.
- Приведение ряда к стационарному
- Прогнозирование с помощью однослойной нейронной сети
- Прогнозирование временных рядов с помощью рекуррентных нейронных сетей
- Прогнозирование временных рядов
- Часть 1. Прогнозирование на основе одномерного временного ряда
- Часть 2: Прогнозирование на основе многомерного временного ряда
- Следующие шаги
Временные ряды. Простые решения

В этой статье мы рассмотрим несколько простых подходов прогнозирования временных рядов.
Материал, изложенный в статье, на мой взгляд, хорошо дополняет первую неделю курса «Прикладные задачи анализа данных» от МФТИ и Яндекс. На обозначенном курсе можно получить теоретические знания, достаточные для решения задач прогнозирования рядов динамики, а в качестве практического закрепления материала предлагается с помощью модели ARIMA библиотеки scipy сформировать прогноз заработной платы в Российской Федерации на год вперед. В статье, мы также будем формировать прогноз заработной платы, но при этом будем использовать не библиотеку scipy, а библиотеку sklearn. Фишка в том, что в scipy уже предусмотрена модель ARIMA, а sklearn не располагает готовой моделью, поэтому нам придется потрудиться ручками. Таким образом, нам для решения задачи, в каком то смысле, необходимо будет разобраться как устроена модель изнутри. Также, в качестве дополнительного материала, в статье, задача прогнозирования решается с помощью однослойной нейронной сети библиотеки pytorch.
Весь код написан на python 3 в jupyter notebook. Более того, notebook устроен таким образом, что вместо данных о заработной плате можно подставить многие другие ряды динамики, например данные о ценах на сахар, поменять период прогнозирования, валидации и обучения, добавить иные внешние факторы и сформировать соответствующий прогноз. Другими словами, в работе используется простенький самописный тренажерчик, с помощью которого можно прогнозировать различные ряды динамики. Код можно посмотреть здесь
План статьи
Краткое описание тренажера
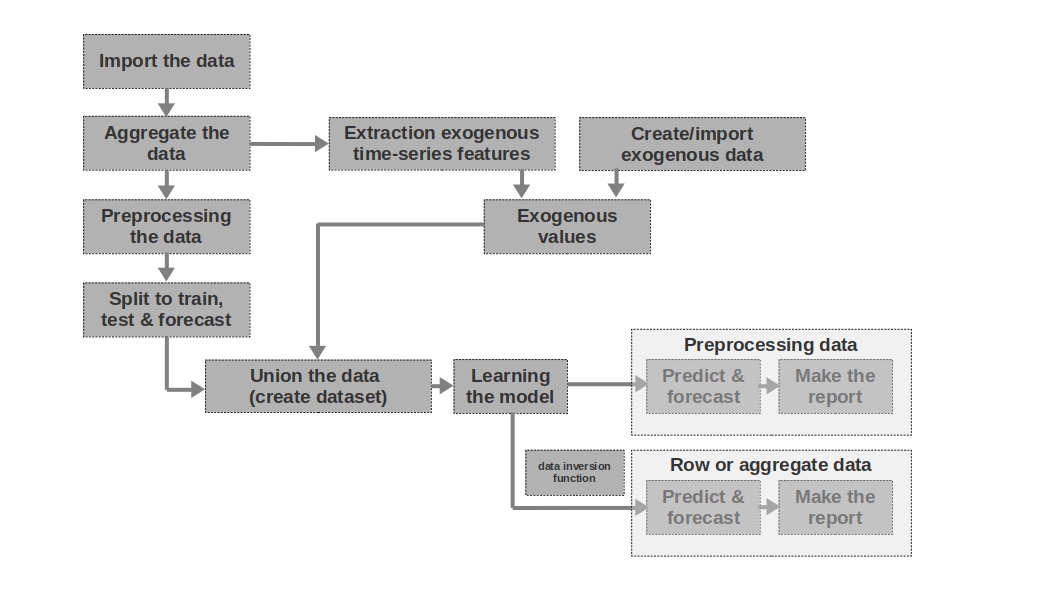
Import the data
Здесь все просто — импортируем данные. Иногда бывает так, что сырых данных достаточно для формирования более-менее внятного прогноза. Именно первый и второй прогнозы в статье моделируются на основании сырых данных, то есть для прогноза заработной платы используются необработанные данные о заработной плате в прошлые периоды.
Aggregate the data
В статье не используется агрегация данных ввиду отсутствия необходимости. Однако зачастую, данные могут быть представлены неравными временными интервалами. В таком случае, просто необходимо их агрегировать. Например, данные с торгов ценными бумагами, валютой и другими финансовыми инструментами необходимо агрегировать. Обычно берут среднее значение в интервале, но можно и максимальное, минимальное, стандартное отклонение и другие статистики.
Preprocessing the data
В нашем случае, речь идет в первую очередь о предобработке данных, благодаря которой, временной ряд приобретает свойство гомоскедастичности (через логарифмирование данных) и становится стационарным (через дифференцирование ряда).
Split to train, test & forecast
В этом блоке кода временные ряды разбиваются на периоды обучения, тестирования и прогнозирования путем добавления нового столбца с соответствующими значениями «train», «test», «forecast». То есть, мы не создаем три отдельных таблицы для каждого периода, а просто добавляем столбец, на основании, которого в дальнейшем будем разделять данные.
Extraction exogenous time-series features
Бывает полезным выделить дополнительные внешние (экзогенные) признаки из временного ряда. Например, указать выходной это день или нет, указать количество дней в месяце (или количество рабочих дней в месяце) и др. Как правило эти признаки «вытаскиваются» из самого временного ряда без какого либо ручного вмешательства.
Create/import exogenous data
Не всю информацию можно «вытащить» из временного ряда. Иногда могут потребоваться дополнительные внешние данные. Например, какие-то эпизодические события, которые оказывают сильное влияние на значения временного ряда. Такими событиями могут быть даты начала военных действий, введения санкций, природные катаклизмы и др. В работе такие факторы не рассматриваются, однако возможность их использования стоит иметь в виду.
Exogenous values
В этом блоке кода мы объединяем все экзогенные данные в одну таблицу.
Union the data (create dataset)
В этом блоке кода мы объединяем значения временного ряда и экзогенных признаков в одну таблицу. Другими словами — готовим датасет, на основании, которого будем обучать модель, тестировать качество и формировать прогноз.
Learning the model
Здесь все понятно — мы просто обучаем модель.
Preprocessing data: predict & forecast
В случае, если мы для обучения модели использовали предобаботанные данные (логарифмированные, обработанные функцией бокса-кокса, стационарный ряд и др.), то качество модели для начала оценивается на предобработанных данных и только потом уже на «сырых» данных. Если, мы данные не предобрабатывали, то данный этап пропускается.
Row data: predict & forecast
Данный этап является заключительным. Если, модель обучалась на предобработанных данных, например, мы их прологарифмировали, то для получения прогноза заработной платы в рублях, а не логарифма рублей, нам следует перевести прогноз обратно в рубли.
Также хотелось бы отметить, что в статье используется одномерный временной ряд для предсказания заработной платы. Однако ничего не мешает использовать многомерный ряд, например добавить данные курса рубля к доллару или какой-либо другой ряд.
Решение в лоб
Будем считать, что данные о заработной плате в прошлом, могут аппроксимировать заработную плату в будущем. Иначе можно сказать — размер заработной платы, например, в январе зависит от того, какая заработная плата была в декабре, ноябре, октябре,…
Давайте возьмем значения заработной платы в 12-ть прошлых месяцев для предсказания заработной платы в 13-й месяц. Другими словами для каждого целевого значения у нас будет 12 признаков.
Признаки будем подавать на вход Ridge Regression библиотеки sklearn. Параметры модели берем по умолчанию за исключением параметра alpha, его установили на 0, то есть по сути мы используем обычную регрессию.
Это и есть решение в лоб — оно самое простое:) Бывают ситуации, когда нужно очень срочно дать хоть какой-то результат, а времени на какую-либо предобработку просто нет или не хватает опыта, чтобы оперативно обработать или добавить данные. Вот в таких ситуациях, можно в качестве baseline использовать сырые данные для построения прогноза. Забегая вперед, отмечу, что качество модели оказалось сопоставимо с качеством моделей, в которых используется предобработка данных.
Давайте посмотрим, что у нас получилось.
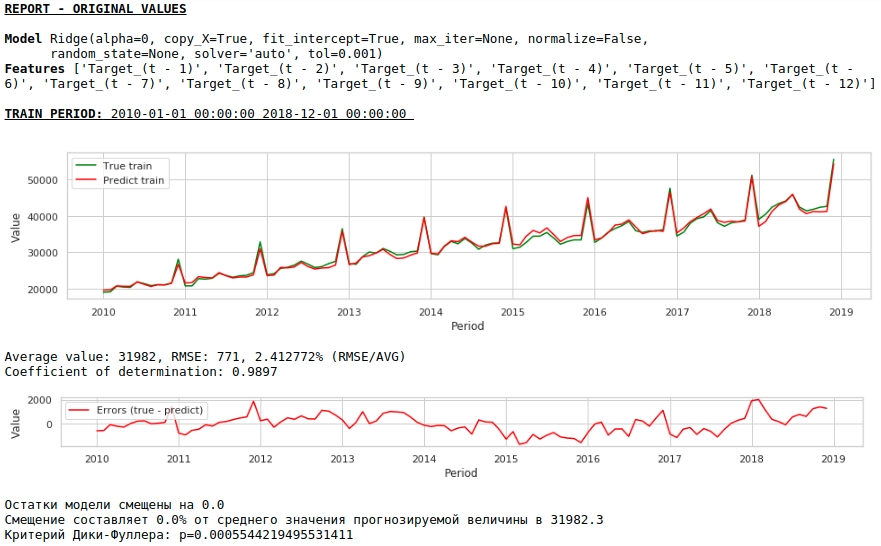
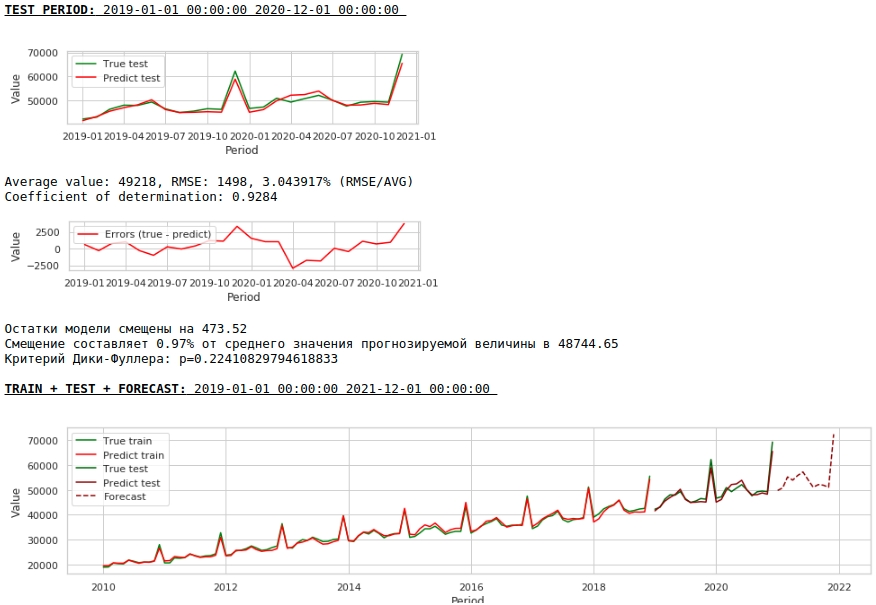
На первый взгляд результат выглядит хоть и неидеально, но близко к действительности.
В соответствии со значениями коэффициентов регрессии, наибольшее влияние на прогноз заработной платы оказывает значение заработной платы ровно год назад.
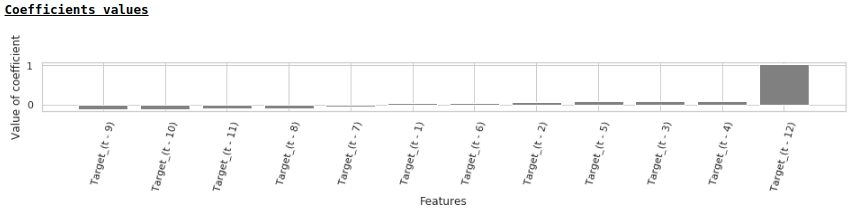
Попробуем добавить в модель экзогенные переменные.
Добавление экзогенных переменных
Мы будем использовать 2 внешних признака: количество дней в месяце и номер месяца (от 1 до 12). Признак «Номер месяца» мы бинаризируем, в итоге у нас получится 12 столбцов для каждого месяца со значениями 0 или 1.
Сформируем новый датасет и посмотрим на качество модели.
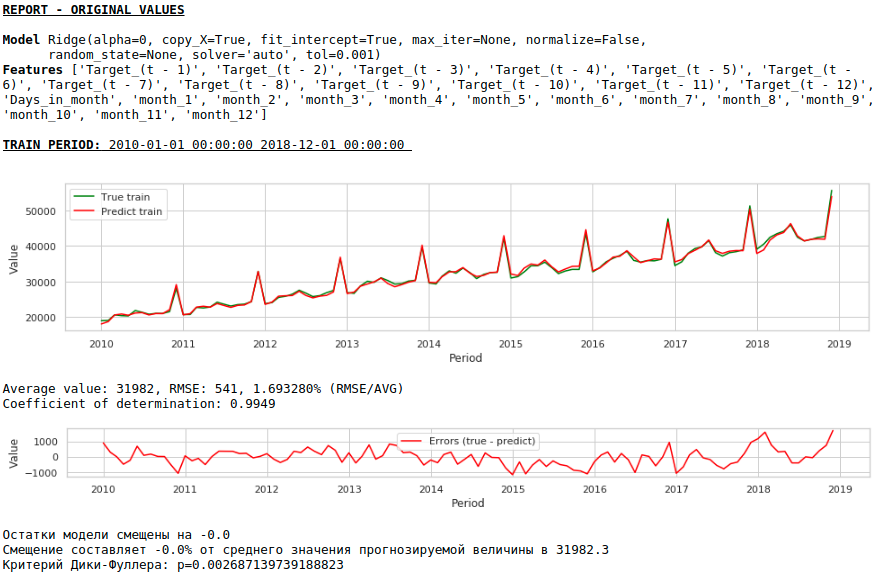
Качество получилось ниже. Визуально заметно, что прогноз выглядит не совсем правдоподобно в части роста заработной платы в декабре.
Давайте теперь проведем первую предобработку данных.
Коррекция гетероскедастичности.
Если мы посмотрим на график заработной платы за период с 2010 по 2020 гг, то мы увидим, что ежегодно разброс заработной платы внутри года между месяцами растет.
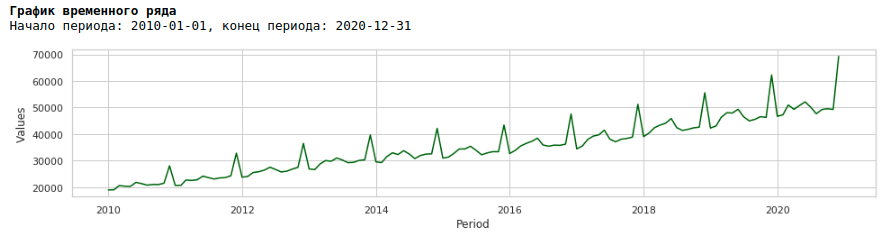
Ежегодный рост дисперсии от месяца к месяцу приводит к гетероскедастичности. Для улучшения качества прогнозирования нам следует избавиться от этого свойства данных и привести их к гомоскедастичности.
Для этого воспользуемся обычным логарифмированием и посмотрим как выглядит прологарифмированный ряд.
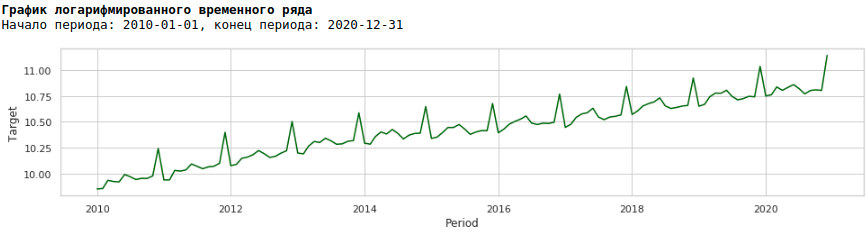
Обучим модель на прологарифмированном ряду
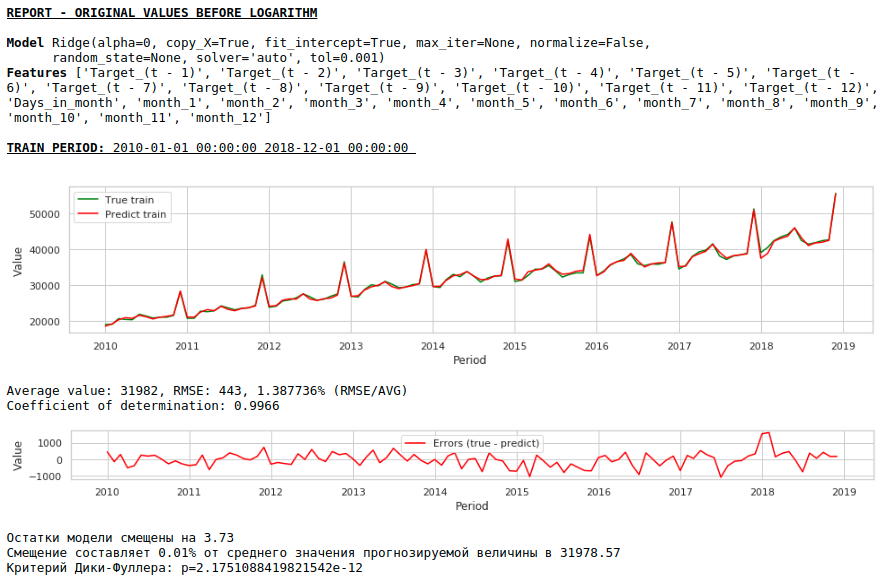
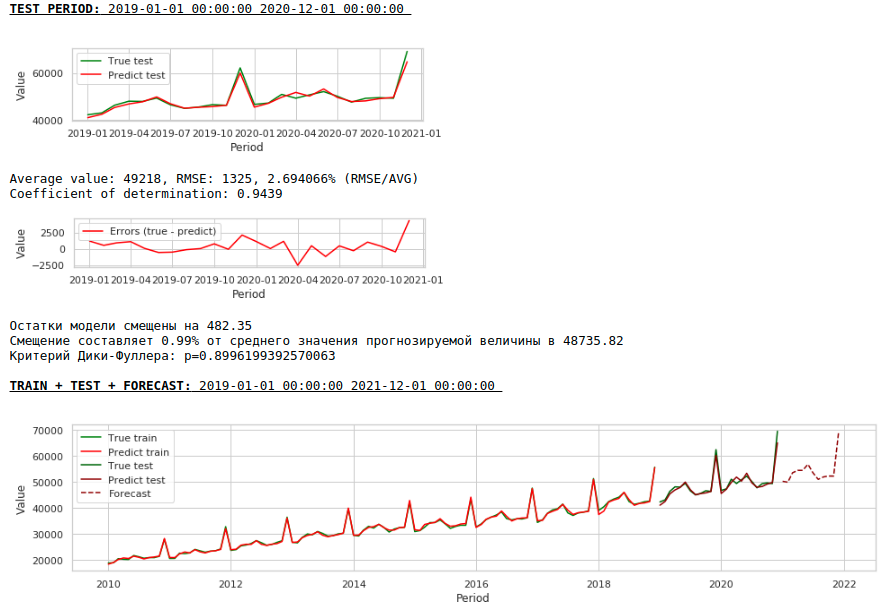
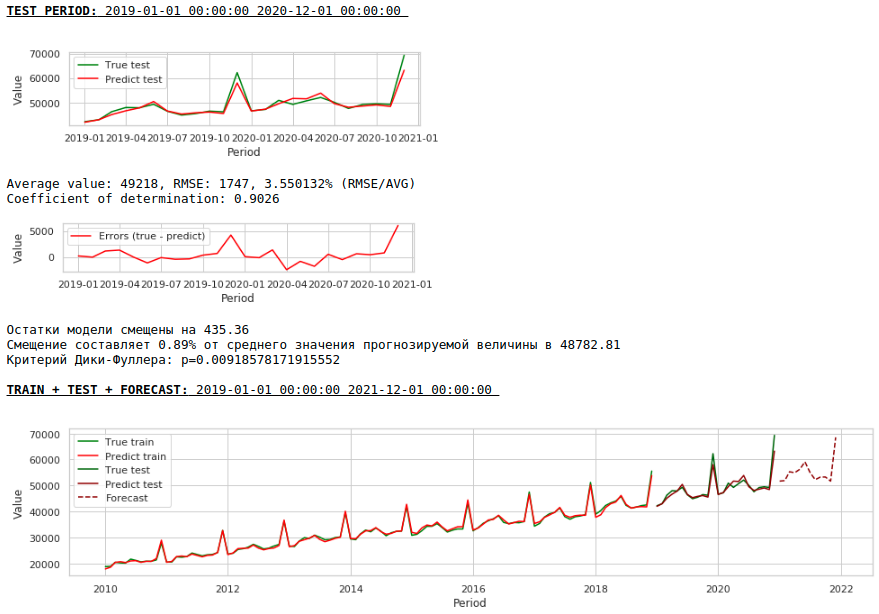
В итоге качество предсказаний на обучающей и тестовой выборках действительно улучшилось, однако прогноз на 2021 год по сравнению с прогнозом первой модели визуально выглядит менее правдоподобным. Скорее всего использование экзогенных факторов ухудшает модель.
Приведение ряда к стационарному
Приводить ряд к стационарному будем следующим образом:
- Определяем разницу между целевым значением заработной платы и значением год назад: t — (t-12) = dif_1
- Определяем разницу между полученным и смещенным на 1 месяц значением: dif_1 — (dif_1-1) = dif_2
В итоге получаем следующий временной ряд.
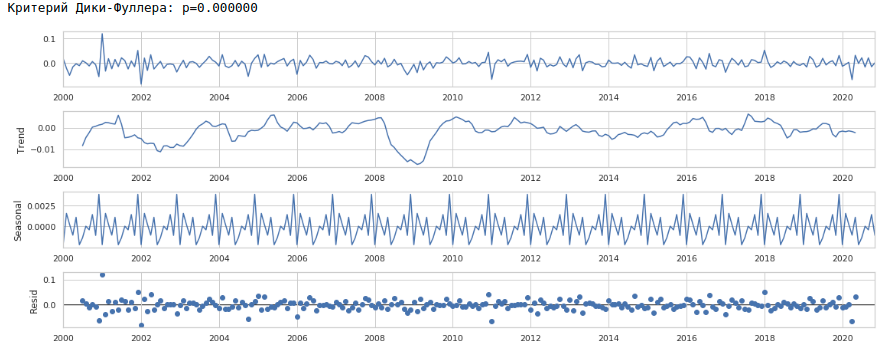
Ряд действительно выглядит стационарным, об этом также говорит значение критерия Дики-Фуллера.
Ожидать хорошее качество предсказаний на обучающей и тестовой выборках на обработанных данных, то есть на стационарном ряду не приходится, так как по сути, в этом случае модель должна предсказывать значения белого шума. Но нам, для прогнозирования заработной платы, уже совсем не обязательно использовать регрессию, так как, приводя ряд к стационарному, мы по-простому говоря, определили формулу аппроксимации целевой переменной. Но мы не будем отходить от канонов и воспользуемся регрессионной моделью, к тому же у нас есть экзогенные факторы.
Давайте посмотрим, что получилось.
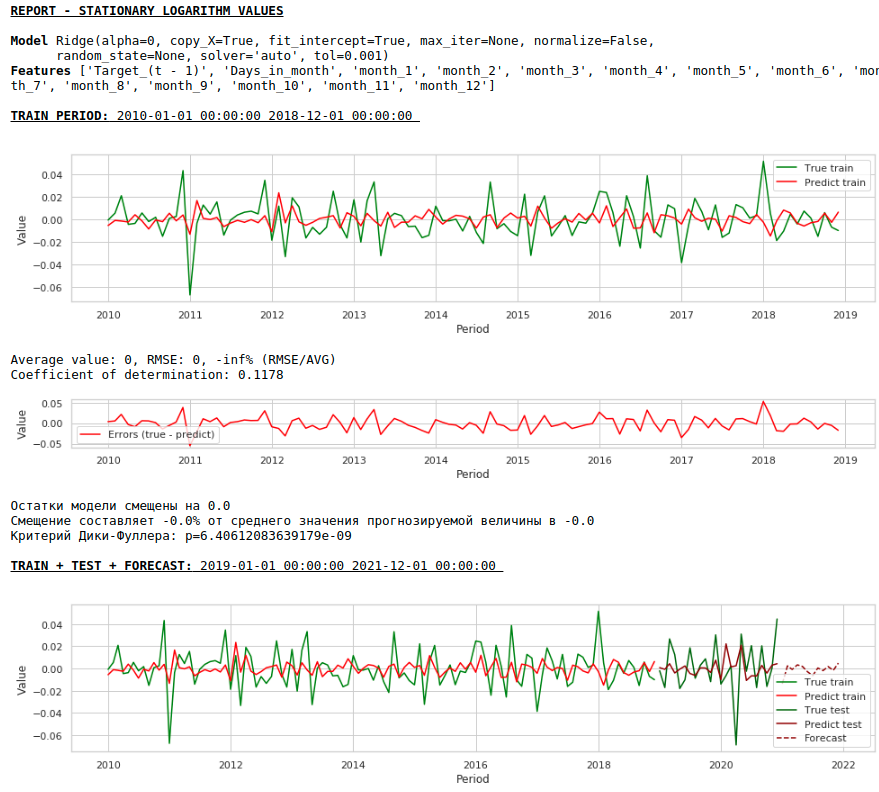
Вот так выглядит предсказание стационарного ряда. Как и ожидали — не очень-то и хорошо 🙂
А вот предсказание и прогноз заработной платы.
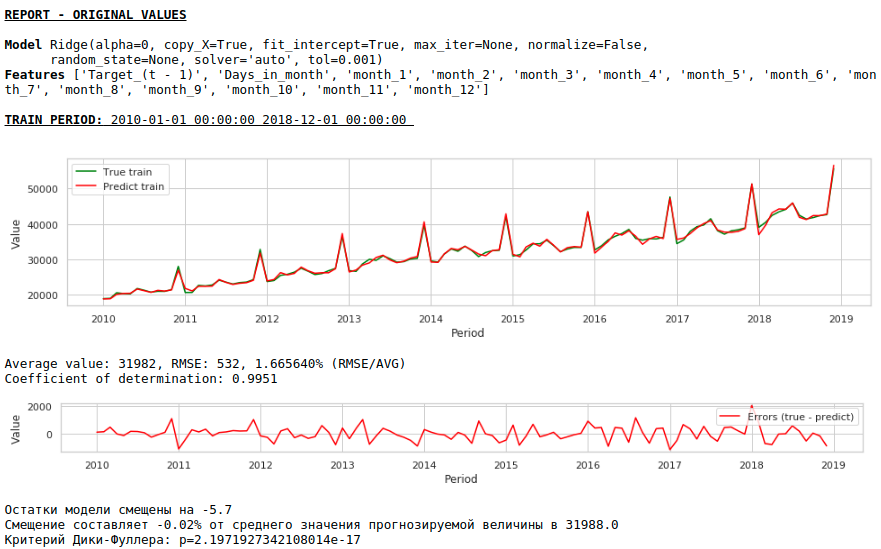
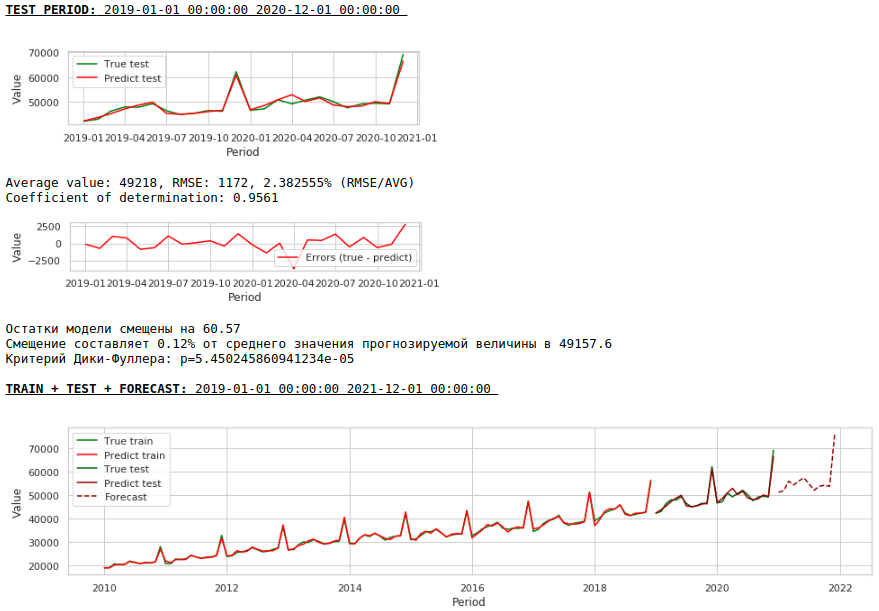
Качество заметно улучшилось и прогноз визуально стал выглядеть правдоподобным.
Теперь сформируем прогноз без использования экзогенных переменных
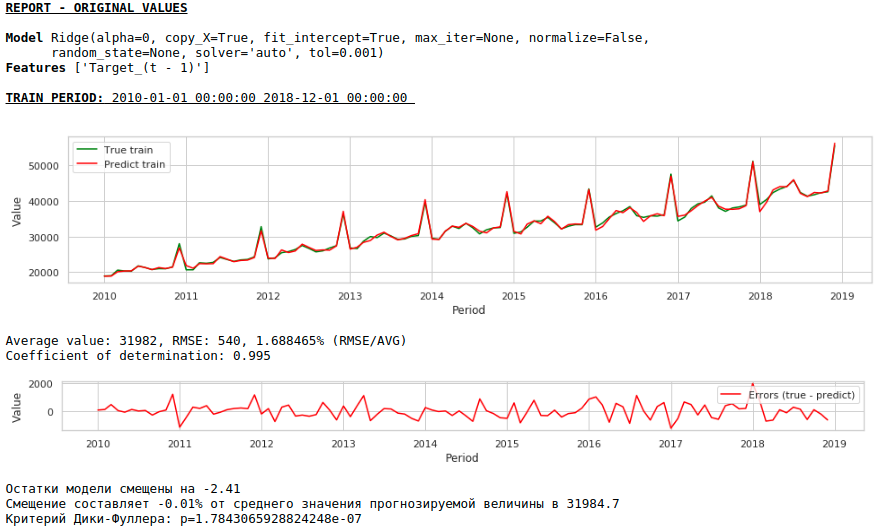
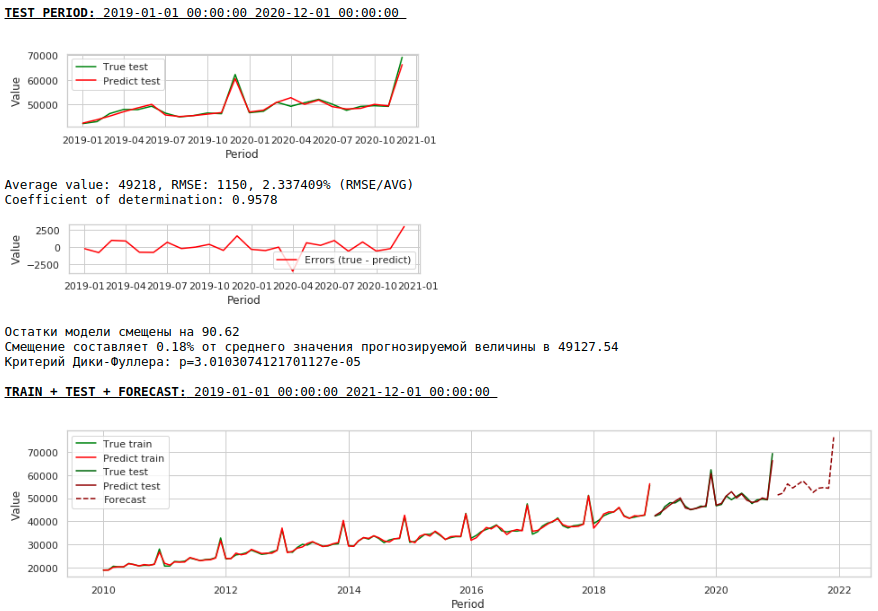
Качество еще улучшилось и правдоподобность прогноза сохранилась 🙂
Прогнозирование с помощью однослойной нейронной сети
На вход нейронной сети будем подавать имеющиеся датасеты. Так как наша сеть однослойная, то по сути это и есть та же самая линейная регрессия с незамысловатыми модификациями и ожидать сильно большую разницу в качестве предсказаний не стоит.
Для начала посмотрим на саму сеть
Теперь пару слов о том, как будем ее обучать.
- Фиксируем random seed для целей воспроизводимости результата
- Инициализируем модель
- Задаем функцию потерь — MSELoss
- Выбираем в качестве оптимизатора Adam optimizer
- Указываем начальный шаг обучения и определяем условие, при котором шаг понижается. Отмечу, что правильный выбор шага и его дальнейшее изменение (обычно уменьшение) приносит хорошие плоды
- Указываем количество эпох обучения
- Запускаем обучение
- На вход сети подаем целиком датасет, так как он очень маленький и разбивать его на батчи не имеет смысла
- При обучении, каждую тысячу эпох формируем графики значения функции потерь на обучающей и тестовой выборках. Это позволяет нам контролировать переобучение или не дообучение модели.
Ниже приведен код обучения сети на первом датасете. Для каждого датасета незначительно менялись параметры: количество эпох обучения и шаг обучения.
Не будем рассматривать качество предсказаний для каждого датасета отдельно (желающие могут посмотреть подробности на гите). Давайте сравним итоговые результаты.
Качество на тестовой выборке с использованием Ridge Regression
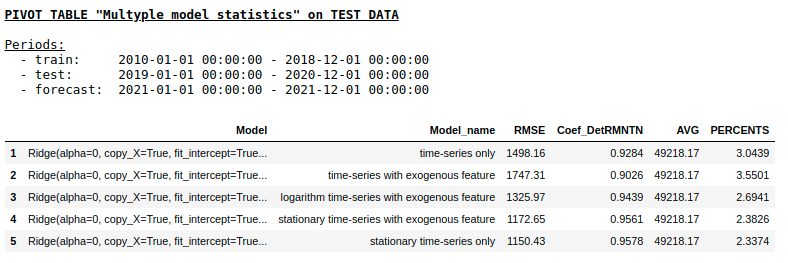
Качество на тестовой выборке с использованием Single layer NN
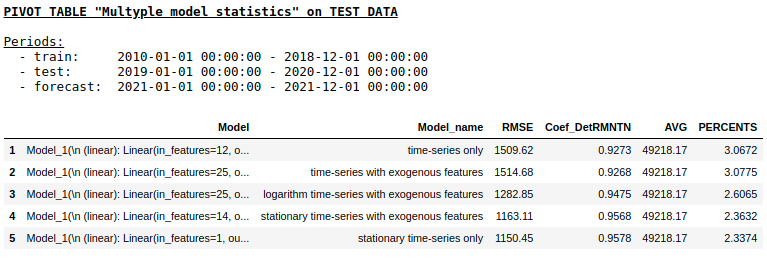
Как мы и ожидали, принципиальной разницы между обычной регрессией и простой однослойной нейронной сетью не оказалось. Конечно, нейронки дают больше маневра для обучения: можно менять оптимизаторы, регулировать шаги обучения, использовать скрытые слои и функции активации, можно пойти еще дальше и использовать рекуррентные нейронные сети — RNN. К слову, лично мне не удалось получить вменяемого качества в данной задаче с использованием RNN, однако на просторах интернета можно встретить много интересных примеров прогнозирования временных рядов с использованием LSTM.
На этом моменте статья подошла к завершению. Надеюсь, материал будет полезен как некий обзор baseline-подходов, применяемых при прогнозировании временных рядов и послужит хорошим практическим дополнением к курсу «Прикладные задачи анализа данных» от МФТИ и Яндекс.
Источник
Прогнозирование временных рядов с помощью рекуррентных нейронных сетей
Удалённый режим работы на фоне всеобщей самоизоляции может привести к весьма дурным последствиям. И эмоциональное выгорание – это ещё куда ни шло: там ведь и до крыши недалеко. В этой связи, как и многие, попробовал «успокоить» себя выделением времени на другие занятия – и начал переводить наиболее интересные статьи с английского языка на русский: «Даёшь машинлёрнинг в массы!».) Нужно воздать должное: здорово отвлекает. Если у вас есть предложения как по смысловому наполнению, так и по переводу данного текста для русскоязычного читателя, присоединяйтесь к обсуждению.

Итак, вашему вниманию представляется перевод страницы Time series forecasting из раздела руководств tensorflow: ссылка. Мои дополнения вместе с иллюстрациями к переводу нацелены помочь с пониманием основных идей в одном из самых интересных направлений ML и эконометрики в целом – прогнозировании временных рядов.
Небольшое вступление перед переводом.
Руководство представляет собой описание выполнения прогнозирования температуры воздуха на основе одномерных временных рядов (univariate time-series) и многомерных временных рядов (multivariate time-series). Для каждой части подаваемые на вход модели данные (input data) должны быть подготовлены соответствующим образом. С учётом рассматриваемого в данном руководстве набора метеорологических данных, разделение имеет следующий вид:
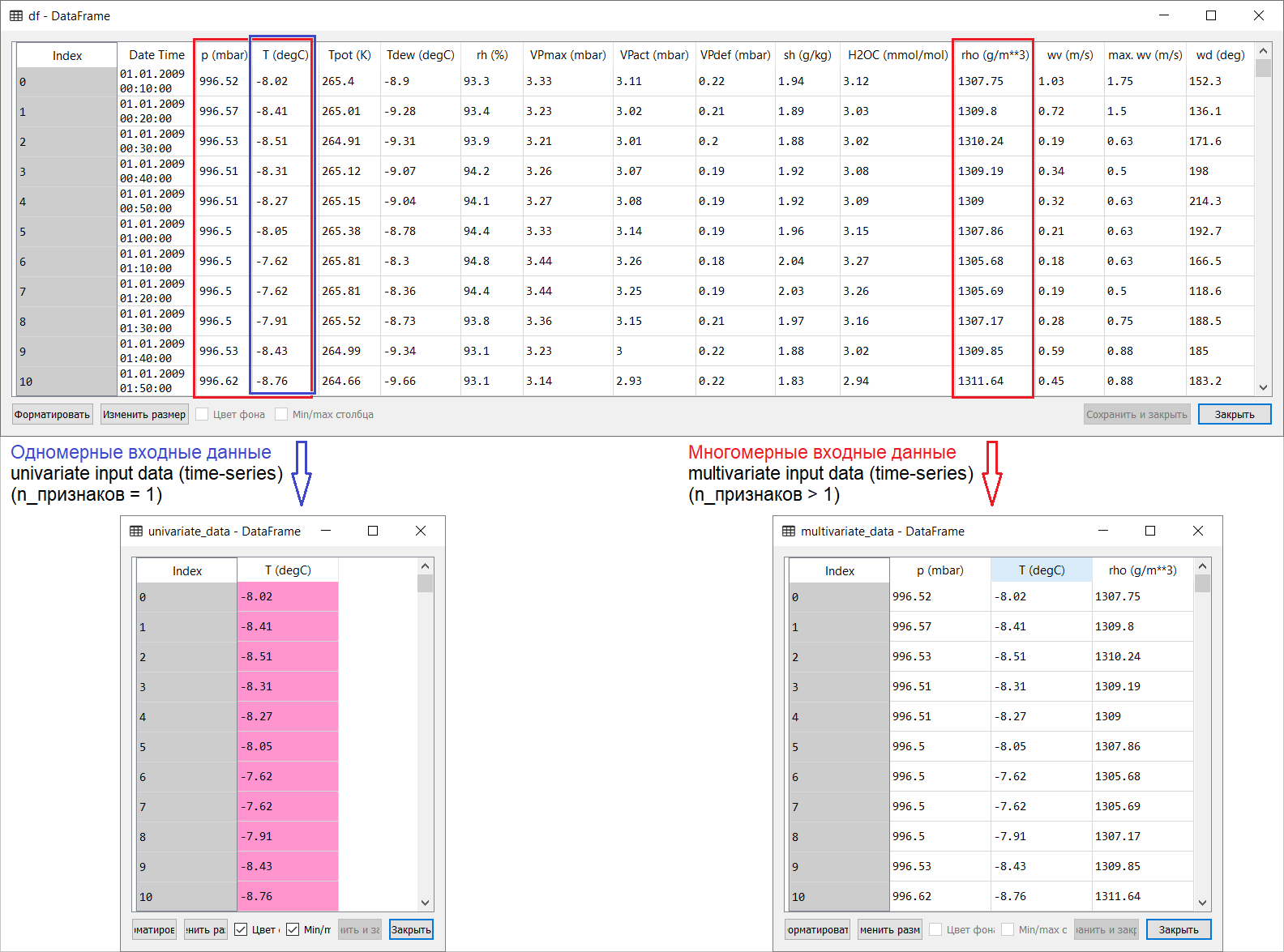
На вопросы о том, что брать за Х а что за Y, то есть как подготовить данные под класс контролируемого обучения, станет ясно из последующих иллюстраций. Отмечу только, что формирование целевого вектора (Y) для работы как с одномерным, так и многомерным временным рядом одинаковое: целевой вектор составляется на основе признака Т(degC) (температура воздуха). Разница между ними «зарыта» в формировании набора признаков, подающихся на вход модели: в случае с одномерным временным рядом для прогнозирования температуры в будущем входной вектор (X) состоит из одного признака: собственно, температуры воздуха; а для многомерного – более чем одного: помимо температуры воздуха в примере рассматриваемого руководства используются p(mbar) (атмосферное давление) и rho(g/m**3) (влажность).
На первый, далеко-поверхностный, взгляд пример с прогнозированием температуры выглядит неубедительно с точки зрения применения многомерного входа: для прогнозирования температуры наиболее релевантным признаком будет температура. Однако это совершенно не так: для выработки качественного прогноза температуры воздуха нужно учитывать множество факторов, вплоть до трения воздуха о земную поверхность и т.п. К тому же на практике некоторые вещи далеко не очевидны, да и целевой вектор может быть в виде той ещё солянки (или борща). В этой связи разведочный анализ данных с отбором наиболее релевантных признаков для последующего формирования многомерного входа является единственным правильным решением.
Итак, перевод руководства представлен ниже. Дополнительный текст будет выделен курсивом.
Прогнозирование временных рядов
Данное руководство представляет собой введение в прогнозирование временных рядов с использованием рекуррентных нейронных сетей (РНС, от англ. Recurrent Neural Network, RNN). Оно состоит из двух частей: в первой описывается прогнозирование температуры воздуха на основе одномерного временного ряда, во второй — на основе многомерного временного ряда.
Набор метеорологических данных
Во всех примерах руководства используются временные последовательности данных о погоде, записанные на гидрометеорологической станции в Институте биогеохимии им. Макса Планка.
В этот набор данных включены замеры 14 различных метеорологических показателей (таких, как температура воздуха, атмосферное давление, влажность), выполняющиеся каждые 10 минут начиная с 2003 года. Для экономии времени и используемой памяти в руководстве будут использоваться данные, охватывающие период с 2009 по 2016 год. Этот раздел набора данных был подготовлен Франсуа Шолле (François Chollet) для его книги «Глубокое обучение на Python» (Deep Learning with Python).
Посмотрим, что у нас имеется.

В том, что период записи наблюдения составляет 10 минут, можно убедиться по вышеприведённой таблице. Таким образом, в течение одного часа у вас будет 6 наблюдений. В свою очередь за сутки накапливается 144 (6×24) наблюдения.
Допустим, вы хотите cпрогнозировать температуру, которая будет через 6 часов в будущем. Этот прогноз вы делаете на основе имеющихся у вас данных за определённый период: например, вы решили использовать 5 дней наблюдений. Следовательно, для обучения модели вы должны создать временной интервал, содержащий последние 720 (5×144) наблюдений (в виду того, что возможны разные конфигурации, данный набор данных является хорошей основой для экспериментов).
Приведенная ниже функция возвращает вышеописанные временные интервалы для обучения модели. Аргумент history_size — это размер последнего временного интервала, target_size – аргумент, определяющий насколько далеко в будущее модель должна научиться прогнозировать. Другими словами, target_size – это целевой вектор, который необходимо спрогнозировать.
В обеих частях руководства первые 300 000 строк данных будут использоваться для обучения модели, оставшиеся – для её валидации (проверки). В этом случае объём обучающих данных составляет примерно 2100 дней.
Для обеспечения воспроизводимости результатов устанавливается функция seed.
Часть 1. Прогнозирование на основе одномерного временного ряда
В первой части вы будете обучать модель, используя только один признак – температуру; обученная модель будет использоваться для прогнозирования будущих значений температуры.
Для начала извлечем только температуру из набора данных.
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
И посмотрим, как эти данные изменяются во времени.

Перед обучением искусственной нейронной сети (далее – ИНС) важным шагом является масштабирование данных. Одним из распространённых способов выполнения масштабирования является стандартизация (standardization), выполняемая путём вычитания среднего значения и деления на стандартное отклонение для каждого признака. Вы также можете использовать метод tf.keras.utils.normalize , который масштабирует значения в диапазон [0,1].
Примечание: стандартизация должна выполняться только c использованием обучающих данных.
Выполним стандартизацию данных.
Далее подготовим данные для модели с одномерным входом. На вход в модель будут подаваться последние 20 зарегистрированных наблюдений за температурой, и модель необходимо обучить прогнозировать температуру на следующем шаге по времени.
Результаты применения функции univariate_data .
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
Дополнение: подготовка данных для модели с одномерным входом схематично изображена на следующем рисунке (для удобства на этом и последующих рисунках данные представлены в «сыром» виде, до стандартизации, а также без признака ‘Date time’ в качестве индекса):

Теперь, когда данные соответствующим образом подготовлены, рассмотрим конкретный пример. Передаваемая в ИНС информация выделена синим цветом, красным крестиком обозначено будущее значение, которое ИНС должна спрогнозировать.

Базовое решение (без привлечения машинного обучения)
Прежде чем приступить к обучению модели, установим простое базовое решение (baseline). Оно заключается в следующем: для заданного входного вектора метод базового решения «просматривает» всю историю и прогнозирует следующее значение как среднее из последних 20 наблюдений.
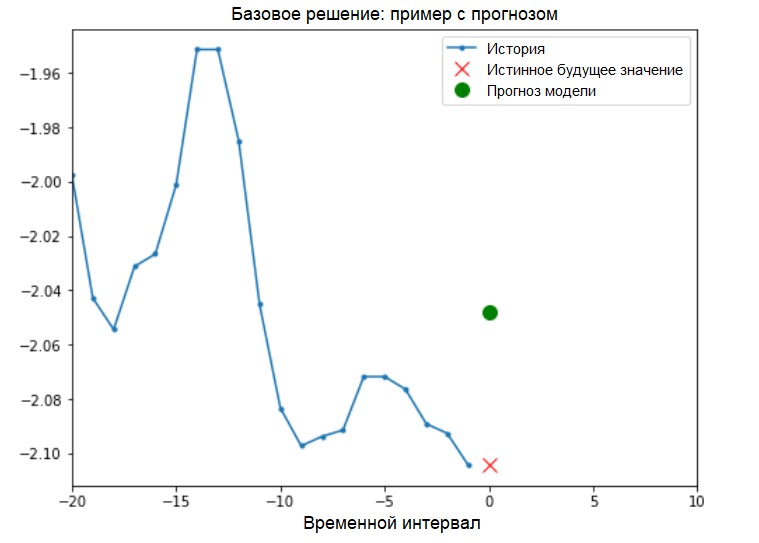
Посмотрим, сможем ли мы превзойти результат «усреднения», использую рекуррентную нейронную сеть.
Рекуррентная нейронная сеть
Рекуррентная нейронная сеть (РНС) — это тип ИНС, который хорошо подходит для решения задач, связанных с временными рядами. РНС шаг за шагом обрабатывает временную последовательность данных, перебирая её элементы и сохраняя внутреннее состояние, полученное при обработке предыдущих элементов. Более подробную информацию о РНС вы можете найти в следующем руководстве. В данном руководстве будет использоваться специализированный слой РНС, который называется «Долгая краткосрочная память» (англ. Long Short-Term Memory, LSTM).
Далее с помощью tf.data выполним перемешивание (shuffle), пакетирование (batch) и кэширование (cache) набора данных.
Подробнее про методы shuffle, batch и cache на странице tensorflow:
Следующая визуализация должна помочь понять, как выглядят данные после пакетной обработки.

Видно, что LSTM требует определённой формы ввода данных, которые ему предоставляются.
Проверим выход модели.
В общем плане РНС работают с последовательностями (sequences). Это означает, что подаваемые на вход модели данные должны иметь следующую форму:
[наблюдения, временной интервал, кол-во признаков]
Форма обучающих данных для модели с одномерным входом имеет следующий вид:
print(x_train_uni.shape)
(299980, 20, 1)
Далее займёмся обучением модели. Из-за большого размера набора данных и в целях экономии времени каждая эпоха будет проходить только 200 шагов (steps_per_epoch=200) вместо полных данных обучения, как это обычно делается.
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] — 2s 11ms/step — loss: 0.4075 — val_loss: 0.1351
Epoch 2/10
200/200 [==============================] — 1s 4ms/step — loss: 0.1118 — val_loss: 0.0360
Epoch 3/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0490 — val_loss: 0.0289
Epoch 4/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0444 — val_loss: 0.0257
Epoch 5/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0299 — val_loss: 0.0235
Epoch 6/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0317 — val_loss: 0.0224
Epoch 7/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0287 — val_loss: 0.0206
Epoch 8/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0263 — val_loss: 0.0200
Epoch 9/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0254 — val_loss: 0.0182
Epoch 10/10
200/200 [==============================] — 1s 4ms/step — loss: 0.0228 — val_loss: 0.0174
Прогнозирование с использованием простой модели LSTM
После выполнения подготовки простой LSTM-модели, выполним несколько прогнозов.

Выглядит лучше, чем базовый уровень.
Теперь, когда вы ознакомились с основами, давайте перейдем ко второй части, в которой описывается работа с многомерным временным рядом.
Часть 2: Прогнозирование на основе многомерного временного ряда
Как было сказано, исходный набор данных содержит 14 различных метеорологических показателей. Для простоты и удобства во второй части рассматриваются только три из них — температура воздуха, атмосферное давление и плотность воздуха.
Чтобы использовать больше признаков, их названия нужно добавить в список feature_considered.
Посмотрим, как эти показатели изменяются во времени.
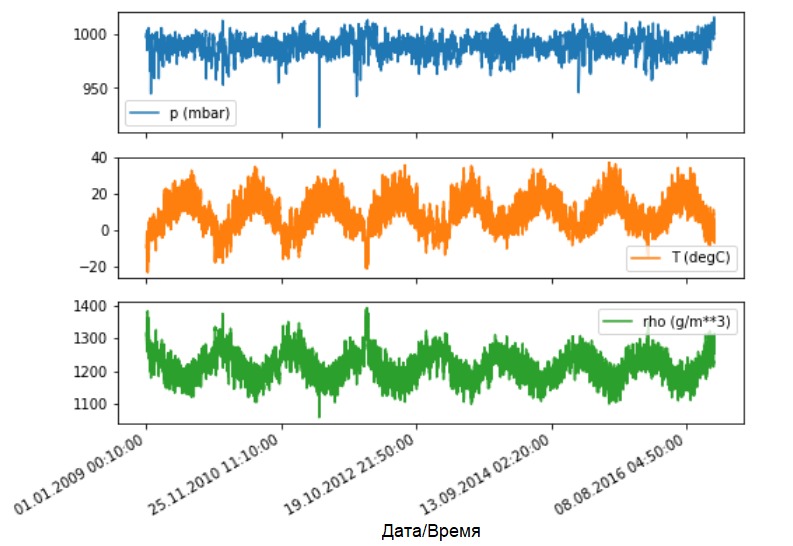
Как и ранее, первым шагом будет выполнение стандартизации набора данных с вычислением среднего значения и стандартного отклонения обучающих данных.
Далее в руководстве будет рассказано о точечном и интервальном прогнозировании.
Суть в следующем. Если вам нужно, чтобы модель прогнозировала одно значение в будущем (например, значение температуры через 12 часов) (one-step/single step model), то и обучить модель вы должны таким образом, чтобы она прогнозировала только одно значение в будущем. Если задача состоит в прогнозировании интервала значений в будущем (например, ежечасные значения температуры в течение следующих 12 часов) (multi-step model), то и модель должна быть обучена прогнозировать интервал значений в будущем.

В данном случае модель обучается прогнозированию одного значения в будущем на основе некой имеющейся истории.
Приведенная ниже функция выполняет ту же задачу организации временных интервалов лишь с тем отличием, что здесь она отбирает последние наблюдения на основе заданного размера шага.
В данном руководстве ИНС оперирует данными за последние пять (5) дней, то есть 720 наблюдениями (6х24х5). Допустим, что отбор данных проводится не каждые 10 минут, а каждый час: в течение 60 минут резкие изменения не ожидаются. Следовательно, историю последних пяти дней составляют 120 наблюдений (720/6). Для модели, выполняющей точечное прогнозирование, целью является значение температуры через 12 часов в будущем. В этом случае целевой вектор будет составлять температура после 72 (12х6) наблюдений (см. следующее дополнение. – Прим. переводчика).
Проверим временной интервал.
Single window of past history : (120, 3)
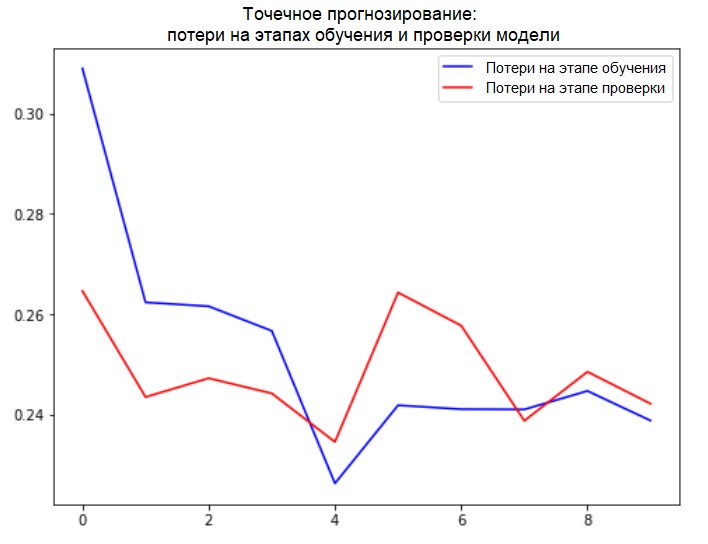
Проверим нашу выборку и выведем кривые потерь на этапах обучения и проверки.
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] — 4s 18ms/step — loss: 0.3090 — val_loss: 0.2646
Epoch 2/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2624 — val_loss: 0.2435
Epoch 3/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2616 — val_loss: 0.2472
Epoch 4/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2567 — val_loss: 0.2442
Epoch 5/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2263 — val_loss: 0.2346
Epoch 6/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2416 — val_loss: 0.2643
Epoch 7/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2411 — val_loss: 0.2577
Epoch 8/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2410 — val_loss: 0.2388
Epoch 9/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2447 — val_loss: 0.2485
Epoch 10/10
200/200 [==============================] — 2s 9ms/step — loss: 0.2388 — val_loss: 0.2422
Подготовка данных для модели с многомерным входом, выполняющей точечное прогнозирование, схематично изображена на следующем рисунке. Для удобства и более наглядного представления подготовки данных аргумент STEP равен 1. Обратите внимание, что в приводимых функциях-генераторах аргумент STEP предназначен только для формирования истории, а не для целевого вектора.
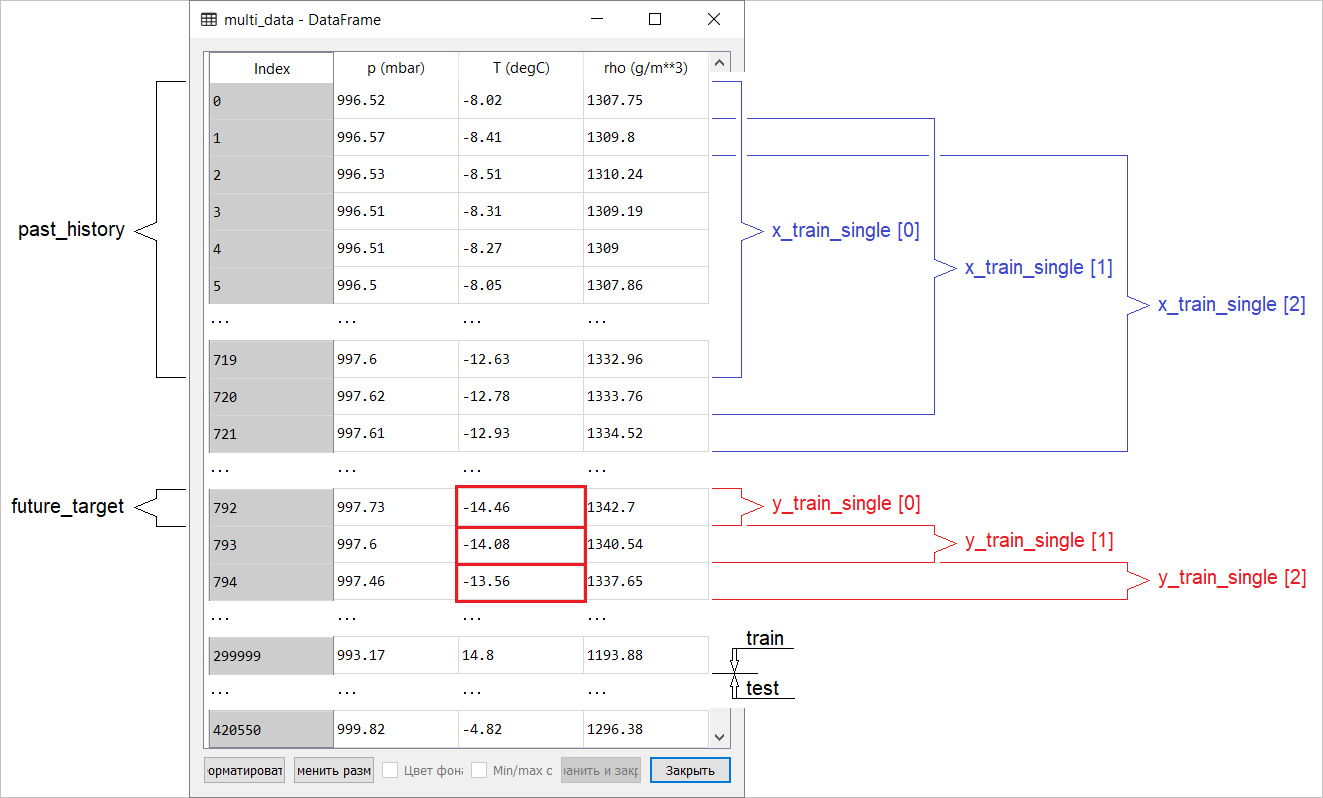
В этом случае x_train_single имеет форму (299280, 720, 3) .
При STEP=6 , форма примет следующий вид: (299280, 120, 3) и скорость выполнения функции увеличиться в разы. Вообще нужно отдать должное программисту: представленные в руководстве генераторы очень прожорливые в плане потребляемой памяти.
Выполнение точечного прогноза
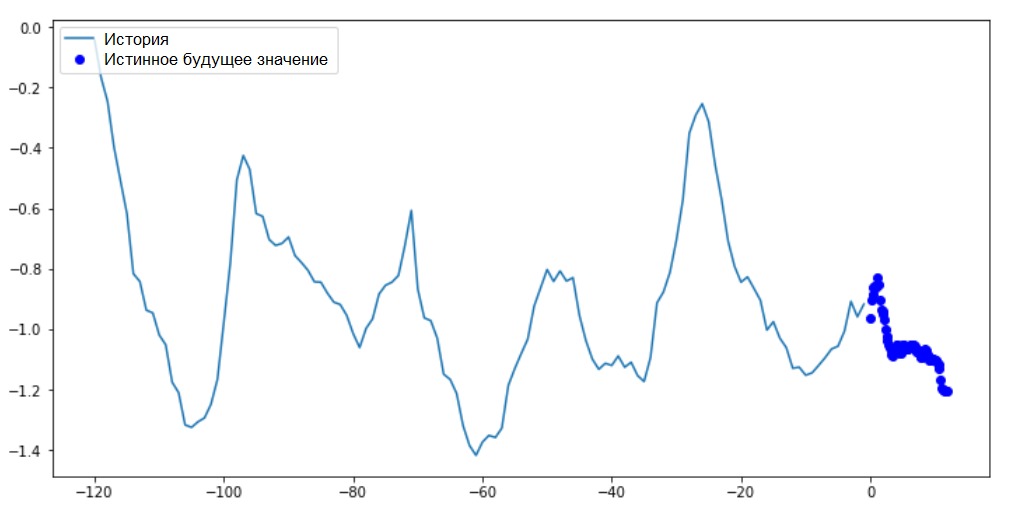
Теперь, когда модель обучена, выполним несколько пробных прогнозов. На вход модели подаётся история наблюдений 3-х признаков за последние пять дней, отобранных каждый час (временной интервал = 120). Так как наша цель заключается в прогнозе только температуры, то синим цветом на графике отображены прошлые значения температуры (история). Прогноз выполнен на полдня в будущее (отсюда и разрыв между историей и спрогнозированным значением).

В этом случае на основе некой имеющейся истории модель обучается прогнозированию интервала будущих значений. Таким образом, в отличие модели, прогнозирующей только на одно значение в будущее, данная модель прогнозирует последовательность значений в будущем.
Допустим, как и в случае с моделью, выполняющей точечное прогнозирование, для модели, выполняющей интервальное прогнозирование, обучающими данными являются почасовые замеры последних пяти дней (720/6). Однако в данном случае модель необходимо обучить прогнозировать температуру на следующие 12 часов. Поскольку наблюдения регистрируются каждые 10 минут, выход (output) модели должен состоять из 72 прогнозов. Для выполнения этой задачи необходимо подготовить набор данных заново, но с другим целевым интервалом.
Single window of past history : (120, 3)
Target temperature to predict : (72,)
Дополнение: отличие в формировании целевого вектора для «интервальной модели» от «точечной модели» видно на следующем рисунке.

На этом и последующих аналогичных графиках история и будущие данные ежечасные.
Так как эта задача немного сложнее, чем предыдущая, то модель будет состоять из двух слоёв LSTM. Наконец, поскольку выполняется 72 прогноза, выход слой насчитывает 72 нейрона.
Проверим нашу выборку и выведем кривые потерь на этапах обучения и проверки.
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] — 21s 103ms/step — loss: 0.4952 — val_loss: 0.3008
Epoch 2/10
200/200 [==============================] — 18s 89ms/step — loss: 0.3474 — val_loss: 0.2898
Epoch 3/10
200/200 [==============================] — 18s 89ms/step — loss: 0.3325 — val_loss: 0.2541
Epoch 4/10
200/200 [==============================] — 18s 89ms/step — loss: 0.2425 — val_loss: 0.2066
Epoch 5/10
200/200 [==============================] — 18s 89ms/step — loss: 0.1963 — val_loss: 0.1995
Epoch 6/10
200/200 [==============================] — 18s 90ms/step — loss: 0.2056 — val_loss: 0.2119
Epoch 7/10
200/200 [==============================] — 18s 91ms/step — loss: 0.1978 — val_loss: 0.2079
Epoch 8/10
200/200 [==============================] — 18s 89ms/step — loss: 0.1957 — val_loss: 0.2033
Epoch 9/10
200/200 [==============================] — 18s 90ms/step — loss: 0.1977 — val_loss: 0.1860
Epoch 10/10
200/200 [==============================] — 18s 88ms/step — loss: 0.1904 — val_loss: 0.1863

Выполнение интервального прогноза
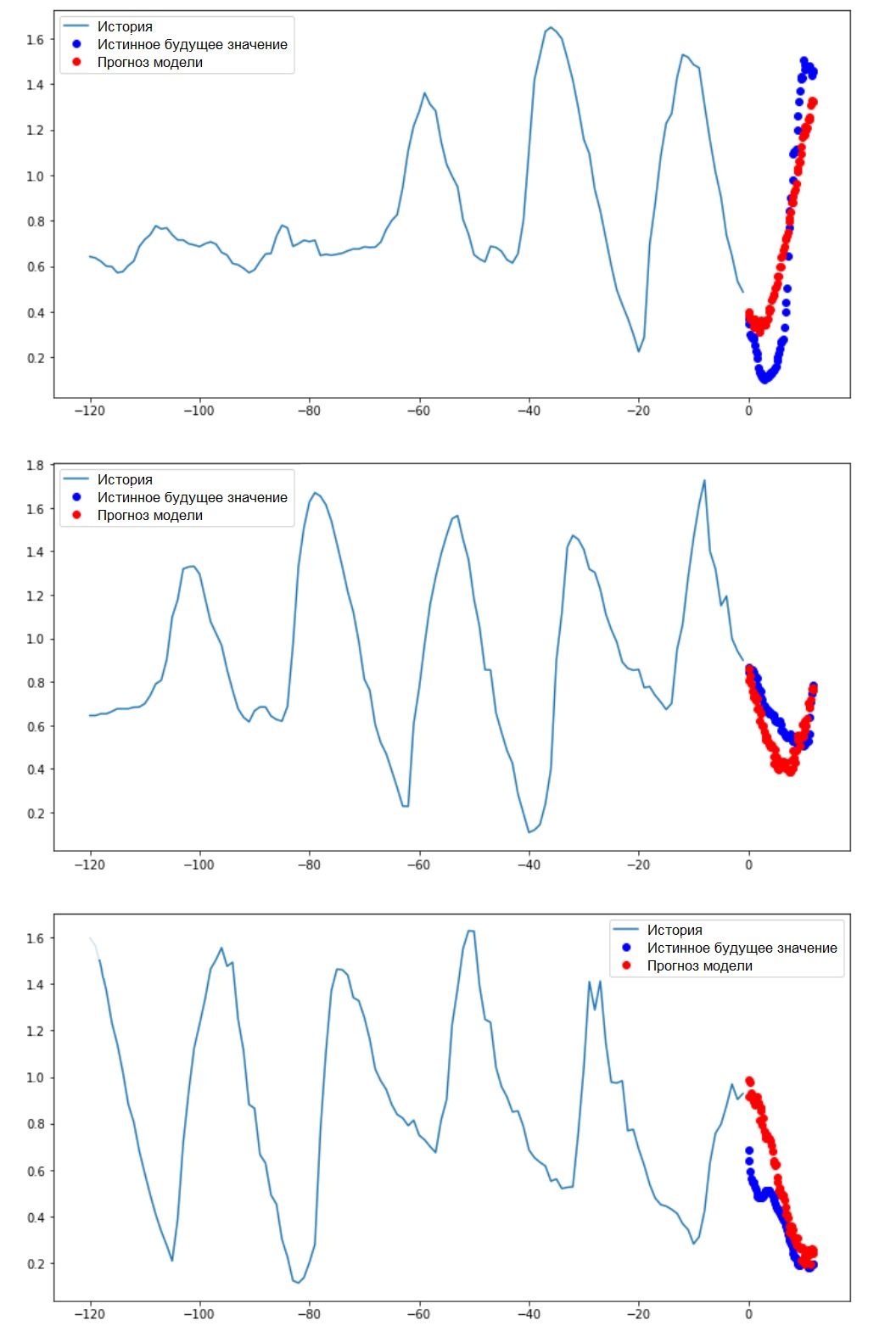
Итак, давайте выясним, насколько успешно обученная ИНС справляется с прогнозами будущих значений температуры.
Следующие шаги
Данное руководство представляет собой краткое введение в прогнозирование временных рядов с использованием РНС. Теперь вы можете попытаться предсказать фондовый рынок и стать миллиардером (в оригинале именно так:). – Прим. переводчика).
Кроме того, вы можете написать собственный генератор для подготовки данных вместо функции uni/multivariate_data с целью более эффективного использования памяти. Также вы можете ознакомиться с работой «time series windowing» и привнести её идеи в данное руководство.
Для дальнейшего понимания рекомендуется прочесть главу 15 книги «Прикладное машинное обучение с помощью Scikit-Learn, Keras и TensorFlow» (Орельен Жерон, 2-е издание) и главу 6 книги «Глубокое обучение на Python» (Франсуа Шолле).
Оставаясь дома, позаботьтесь не только о своём здоровье, но и пожалейте компьютер путём выполнения примеров руководства на усечённом наборе данных. Например, с учётом пропорции 70х30 (тренировка/проверка), можно ограничить его следующим образом:
Источник

